

Disciplinas como la Inteligencia Artificial (IA) y el Machine Learning (ML), también conocido como aprendizaje automático, son utilizadas desde hace ya algunos años facilitando mecanismos y tomas de decisiones en rubros tan variados como el marketing, servicios como atención al cliente o hasta la ciberseguridad. De hecho, el informe “Global AI Adoption” de IBM asegura que el 29% de las organizaciones latinoamericanas ya tiene algún tipo de implementación de estas soluciones, mientras que el 43% está evaluando el uso de la tecnología. Por lo tanto, no solo su uso es una realidad, sino que las proyecciones indican que lo será aún más. Pero, vayamos desde el principio. ¿A qué nos referimos cuando hablamos de Inteligencia Artificial y Machine Learning?
Este artículo forma parte de la serie Tendencias en ciberseguridad para el 2023: ¿en las puertas de una nueva revolución de Internet?
El concepto de Inteligencia Artificial refiere a una disciplina que intenta emular distintos aspectos de la inteligencia humana a través de la tecnología, ya sea su raciocinio para la resolución de problemas, su capacidad para tomar una decisión sobre la base de información recolectada o su capacidad para realizar tareas complejas. Y dentro de la misma encontramos al Machine Learning, que busca, como dice su nombre, que la tecnología aprenda a partir de procesar información recolectada.
Teniendo esto en claro, es sencillo ver por qué la IA y el ML vinieron para solucionar problemáticas para las cuales no existía una solución eficiente. De hecho, es muy probable que nos encontremos en nuestro día a día con un servicio o aplicación que implementa estas tecnologías: Desde la identificación facial para el desbloqueo de nuestro smartphone, pasando por la sugerencia de series que podrían gustarnos a partir de lo que vimos, hasta la detección de códigos maliciosos en las soluciones de seguridad que utilizan las organizaciones.
Y es por ello que gigantes como Amazon, Meta y Google están invirtiendo millones de dólares en investigación, hardware de gran cómputo y mano de obra para desarrollar soluciones que utilicen Inteligencia Artificial, tanto para sus principales productos como para otros campos como la medicina o la agricultura.
El crecimiento que tuvo el Machine Learning durante los últimos 10 años fue muy grande. Considerando que se trata de una tecnología muy compleja podemos decir que fueron años de gran innovación. Esto nos ha llevado a estar constantemente expuestos a noticias y mensajes que nos hablan la importancia del ML para sectores como finanzas, salud, educación, comercio, logística, entre otros. Es claro que la implementación de tecnologías basadas en ML están en auge. Según el informe elaborado por IBM, la adopción de la IA a nivel global registra un crecimiento estable y actualmente el 35% de las empresas reportaron estar utilizando Inteligencia Artificial en sus negocios. Sobre todo las grandes compañías y en industrias como la automotriz o la financiera.
Está claro que adopción de la IA seguirá aumentando. Actualmente el 53% de los profesionales de IT aseguran que en los últimos 24 meses han acelerado el lanzamiento de productos o servicios que utilizan esta tecnología.
Sin embargo, como toda tecnología también tiene su lado B. La capacidad de tomar decisiones o realizar tareas, incluso aquellas que antes parecían imposibles, también puede ser aprovechada por cibercriminales. En este sentido, podemos determinar que estamos tratando con un arma de doble filo.
¿Por qué el ML es un gran aliado para el cibercrimen?
Con respecto a la ciberseguridad, si bien muchas personas conocen las deepfakes, esto es solo una punta. Lo cierto es que no hay tanta visibilidad de los riesgos y el alcance que puede tener el uso de la Inteligencia Artificial por parte de los actores maliciosos. Para comprender los riesgos que implica el uso de estas tecnologías por actores maliciosos es importante comprender que las empresas actualmente optan por adoptar a sus procesos el ML por dos necesidades: optimización y predicción. Por lo tanto, si estas tecnologías ayudan a las empresas a satisfacer estas necesidades, deberíamos preguntarnos si estas mismas necesidades no las tiene también los actores maliciosos.
En cuanto a la optimización, realizar campañas de phishing con el objetivo de recolectar información y realizar un perfilamiento de las personas tiene un costo. Con la ayuda de los procesos de ML un actor de amenazas podría alimentar al algoritmo de ML para que realice un perfilamiento de potenciales víctimas mucho más correcto y conocer qué servicios consumen. En segundo lugar, cuando hablamos de predicción a través de los diversos algoritmos de ML, esta funcionalidad puede ser utilizada por atacantes para predecir qué usuarios son más propensos a ser víctimas.
Por otro lado, ya se han utilizado algoritmos de ML para descifrar contraseñas. Tal como es el caso de un grupo de investigadores que crearon un generador de contraseñas basado en tecnología de aprendizaje profundo que fue capaz de descifrar millones de contraseñas pertenecientes a cuentas reales de LinkedIn.
“Amenazas ¿inteligentes?”
Al hablar de Machine Learning muchas veces se utilizan frases amigables como “algoritmos que aprenden de nosotros” o “programas que responden a datos”. Si bien estas descripciones son demasiado simplistas, también es cierto que nos ofrece la posibilidad de ver este lado B: ¿Qué sucede si el algoritmo que aprende de nosotros es una amenaza?
Un subconjunto de las amenazas que hoy en día están (y seguirán estando) en boga son aquellas que utilizan ingeniería social, o el engaño y manipulación a las víctimas para poder obtener información, credenciales o dinero a cambio. Pero las formas de ingeniería social han sufrido cambios a través de los años: de ser solo correos electrónicos a mensajes en redes sociales, la corrección de errores ortográficos, la compra de certificados válidos para sitios engañosos, y más.
Estos cambios a lo largo del tiempo necesitaron del esfuerzo manual de los atacantes que constantemente han buscado adoptar nuevos comportamientos que hagan más difícil la tarea de detectar su actividad maliciosa, y también adecuarse a los tiempos que corren y a las formas más efectivas de atraer a sus víctimas. Pero, así como existe la posibilidad de aprender cómo funciona una amenaza para detectarla y detenerla más rápidamente, existe la sombría posibilidad de encuadrar el comportamiento humano para algo más que la predicción de la serie con la cual podríamos tener más afinidad: amoldar cada componente de una comunicación de phishing según qué técnica consigue la mayor cantidad de víctimas. Algunas de las características que podrían modificarse con este método podrían ser las excusas utilizadas o el idioma, o también a qué tipo de población llegan, tal como un anuncio dirigido, y de manera automatizada.
Y si hablamos de amenazas que aprenden de nosotros, no podemos dejar de lado la constante preocupación (justificada) por las deepfakes, un concepto que se perfecciona año a año y que seguirá siendo un tema “caliente”. Este término condensa cualquier pieza de información (imágenes, videos y hasta audios) que haya sido generada con algoritmos de aprendizaje profundo para falsificar una identidad y el accionar de una persona. Y el concepto de generar un video de una personalidad conocida realizando alguna acción que no hizo es un concepto preocupante para el ámbito de la ciberseguridad.
Lamentablemente, esto es algo cada vez más frecuente y ya hemos presenciado varios casos reales en los que se han utilizado deepfakes para realizar ataques suplantando la identidad de personalidades como Elon Musk, el CEO de Binance o el CEO de FTX. En todos estos casos los estafadores crearon videos falsos promocionando algún tipo de estafa generalmente relacionada con el mundo de las criptomonedas.
Otra implicación de las deepfakes ha sido su utilización en el conflicto geopolítico entre Rusia Ucrania. Los líderes de ambos países han visto sus imágenes manipuladas para lanzar mensajes falsos, algunos de ellos llegando a las 120.000 visualizaciones en Twitter, reportó Euronews.
Pero no todo son malas noticias: existen algoritmos capaces de determinar si una imagen o video ha sido generado por algún algoritmo de Inteligencia Artificial. Estos observan características que no estarían presentes en contenidos generados naturalmente, como una geometría perfecta en una cara, cambios de luz o colores muy fuertes, bordes duros, entre otros; así como también información específica que obtienen de los metadatos. Un ejemplo de ello es el algoritmo desarrollado por Intel, llamado FakeCatcher, que afirma contar con un 96% de precisión a la hora de detectar imágenes, videos o piezas de audio sintéticas. Incluso LinkedIn anunció en 2022 nuevas funcionalidades de seguridad para identificar perfiles falsos que incluye un modelo de aprendizaje basado en Inteligencia Artificial para identificar perfiles que utilizan generadores de imágenes sintéticas mediante IA. Sin embargo, en muchos casos aún es prematura la evaluación de estos algoritmos y todavía hay pasos que dar en esta área.
“¿Los modelos de ML son vulnerables?”
Como toda tecnología en auge, no solo resulta interesante para los desarrolladores que buscan resolver problemáticas, sino que también llama la atención de los cibercriminales. Si bien el Machine Learning es un gran aliado para la ciberseguridad, también nos expone a ciertos riesgos, ya que esta tecnología presenta una principal vulnerabilidad: la manipulación de los datos.
Ahora bien, similar a lo que ocurrió a principios del 2010 con las tecnologías Cloud cuando muchos consideraban que no iban a tomar fuerza, lo mismo pasó con el ML. Y no paso mucho también hasta que aparecieron las primeras amenazas apuntando a esta tecnología.
¿Qué tipos de amenazas enfrentarán los modelos de ML? Antes de avanzar, si pensamos el proceso de ML en dos etapas, tenemos el entrenamiento del modelo y luego su resultado; es decir, la fase de predicción, también conocida como etapa de inferencia. Para llegar a esta última etapa primero es necesario obtener el modelo, aportarle un nuevo conjunto de datos y entrenar el modelo de ML para que sea capaz de “detectar” o hasta incluso “predecir”.
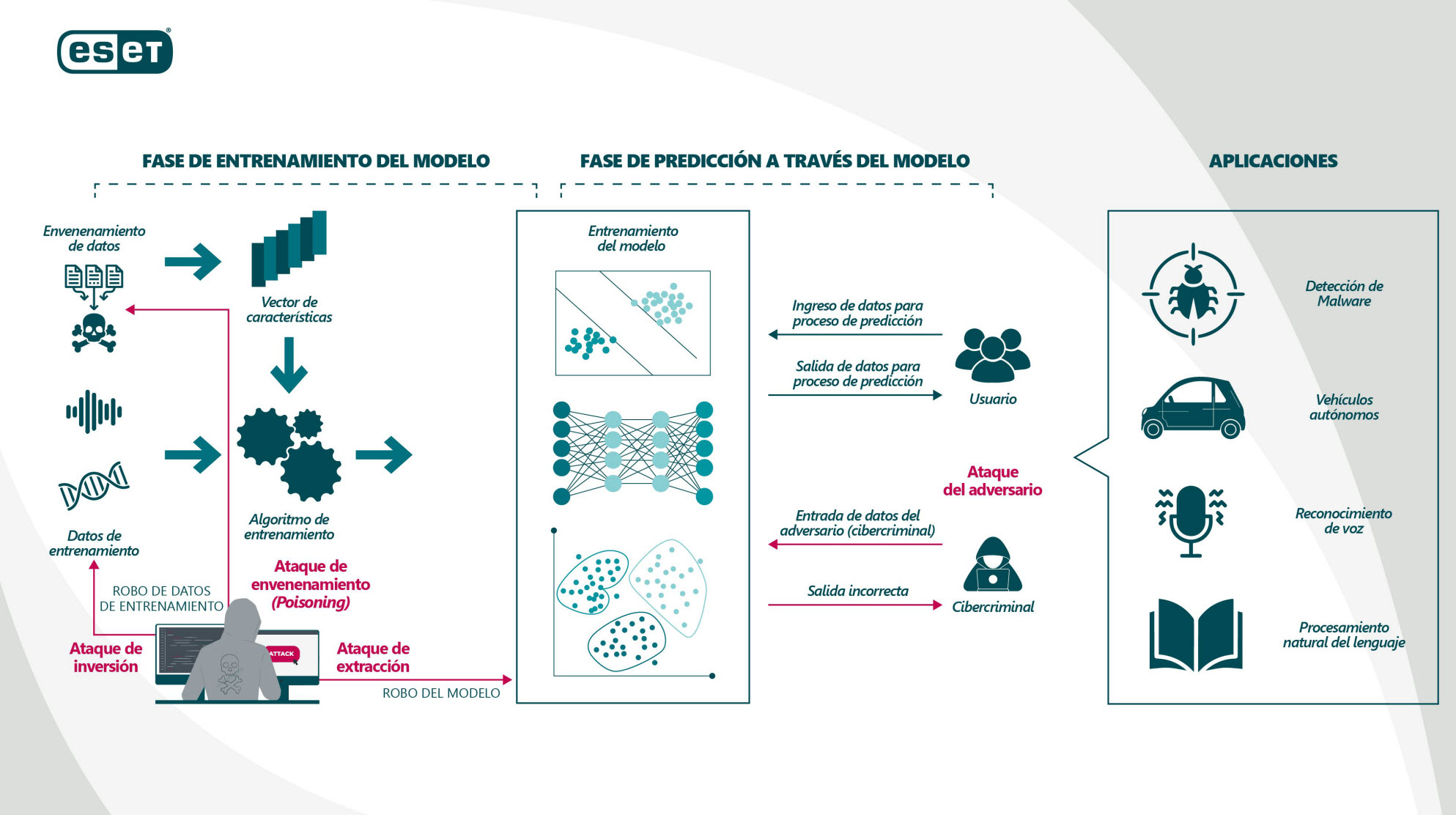
Proceso por el que pasa un sistema de ML hasta ser capaz de detectar o incluso realizar predicciones.
Intrusiones inteligentes
Una vez entrenados, los modelos de ML pueden ser vulnerables a los ataques de envenenamiento. Estos ocurren cuando un cibercriminal presenta datos etiquetados incorrectamente a un clasificador para que el sistema tome decisiones inexactas o con un sesgo a favor de la intención del cibercriminal, por lo cual este tipo de ataque también se no denominada ataques de backdoor.
Cuando hablamos de intrusiones inteligentes nos referimos a que a través de este tipo de ataque el sistema de ML puede aprender un modelo incorrecto y pasar totalmente inadvertido, dado que para la mayoría de las entradas el sistema de aprendizaje automático dará la respuesta correcta. El problema ocurre si, por ejemplo, para ciertas entradas especificas elegidas por el cibercriminal, y solo en estas situaciones, el sistema de aprendizaje da una respuesta diseñada por el atacante.
La gravedad de este tipo de ataque está en que es realmente muy sigiloso, porque para el científico de datos no es algo muy sencillo de detectar a simple vista. Pensemos en un ataque de este tipo apuntando a un sistema de reconocimiento facial. En este caso el atacante podría ajustar el modelo para que ciertos tipos de rostros sean interpretados como los de una persona en particular y así lograr suplantar su identidad ante un sistema de reconocimiento facial y obtener acceso a determinada información.
“¿Qué pasa cuando hablamos de propiedad intelectual?”
Debemos recordar que los modelos de ML son diseñados por desarrolladores de ML bajo un grupo de trabajo. Si bien existen diversas librerías de ML en GitHub disponibles al alcance de cualquiera, es clave resaltar que la inteligencia desarrollada para que el algoritmo piense “por sí solo” es propiedad del equipo de desarrollo, por ende se entiende bien que este tipo de inteligencia es totalmente privada. Según NIST, existen ataques en los cuales se extrae los parámetros o la estructura del modelo a partir de las observaciones de las predicciones del modelo; por lo general, incluidas las probabilidades devueltas para cada clase. Estos ataques no solo representan un robo a la propiedad intelectual, sino que también viola uno de los pilares fundamentales de la seguridad de la información: la confidencialidad.
¿Qué nos depara el futuro?
A lo largo de los últimos diez años hemos visto a los actores maliciosos repetir muchas de las técnicas utilizadas para intentar engañar a las personas; sin embargo, aprovechan cada nueva plataforma que emerge al mercado. Esto es clave mencionarlo porque cuando hablamos de ML tenemos que entender que se trata de un nuevo actor y con un rol clave para el desarrollo de diversos tipos de estafas más complejas. Si bien es más sencillo poder ofrecer recomendaciones a las personas acerca de cómo detectar, por ejemplo, un correo de phishing o hasta incluso cómo evitar el vishing; no es tan sencillo con las la suplantación de identidad de algún familiar o incluso con formas de ingeniería social como las deepfakes.
Los ciberdelincuentes entienden muy bien que utilizar audio o video para la suplantación de identidad mediante deepfakes mejora sus posibilidades de que una estafa sea exitosa. Esto también lo vemos reflejado en distintos reportes que muestran cómo los cibercriminales utilizan cada vez más la dark web para buscar tutoriales o servicios personalizados para crear estos contenidos. Por lo tanto, es de esperarse que la tendencia al uso de deepfakes crezca y se convierta en el futuro en una herramienta para realizar estafas. Si bien aún estamos en una etapa inicial de estos ataques, debemos ser conscientes que estamos ante una amenaza en desarrollo pero con un gran potencial y que debemos prepararnos y capacitarnos para el desafío que supone intentar reducir su impacto.
Las deepfakes suponen un gran problema para las personas, ya que suponen un escenario más complejo de detectar que el de los engaños vía mensaje. Supongamos que un conocido nos llame por una urgencia: ¿cómo dudar en ese momento de que la voz que escuchamos, tan parecida a la de esa persona, no es realmente la de quien dice ser? Las deepfakes representan la evolución a las estafas a las que estamos acostumbrados y no solo representan un desafío para las personas y las organizaciones, sino también para aquellas que trabajan en el ámbito de la ciberseguridad.
Por otro lado, sabemos que muchas empresas se están apoyando en la tecnología de ML para sus procesos. Sin embargo, como ocurre con la evolución y desarrollo de muchas tecnologías, crecen las implementaciones y el desarrollo de estos modelos, pero lamentablemente no siempre teniendo en cuenta la perspectiva de la ciberseguridad en el proceso. Y lo cierto es que los cibercriminales solo necesitan encontrar una grieta en las defensas de un sistema para desplegar un ataque adversario.
De hecho, hace dos años Microsoft aseguraba que los ciberataques a sistemas de Machine Learning eran más comunes de lo que se cree”. Entre 2019 y 2021 los sistemas de Machine Learning utilizados por compañías como Google, Amazon, Microsoft y Tesla han sufrido la manipulación de sus datos, y la tendencia probablemente continúe en los próximos años, con más ataques a estos modelos al tiempo que la adopción seguirá creciendo. Que grandes empresas tecnológicas hayan sufrido el engaño, evasión o uso indebido de sus sistemas de Machine Learning da cuenta de la magnitud del desafío que tienen por delante las empresas. Será clave para lidiar con estos desafíos prepararse desde hoy para saber cómo proteger sistemas de ML ante posibles amenazas informáticas.
Según NIST, algunas recomendaciones para poder darle seguridad a este tipo de tecnologías son: emplear cifrado de datos (como el cifrado homomórfico), privacidad diferencial, estadística robusta y otras mejoras a nivel de robustez.
Mas allá de estos consejos generales, hablar de mejorar las defensas probablemente incluya la necesidad de mayor inversión y capacitación, pero la realidad muestra que estos modelos de ML ya controlan muchos procesos de nuestra vida diaria, con lo cual no hay tiempo que perder y debemos pensar en lo que viene. Como dijo Vicent Rijmen, uno de los padres de la criptografía, la seguridad siempre implica un coste en rendimiento.
Invitamos a escuchar el episodio de diciembre del podcast Conexión Segura, donde los investigadores de ESET hablaron en profundidad de estas tres tendencia y explicaron cuáles son los desafíos para la ciberseguridad.



