

El Machine Learning (ML) o aprendizaje automático es una subárea de la inteligencia artificial (AI) que ha tomado más relevancia en el campo de la informática, ya que su uso se fue multiplicando en diversas disciplinas, como en publicidad, medicina, detección de fraude, traducciones, reconocimiento de voz y facial, entre otros.
Pero como toda tecnología en auge, no solo resulta interesante para los desarrolladores que buscan resolver problemáticas, sino que también llama la atención de los cibercriminales. Si bien el machine learning es un gran aliado para la ciberseguridad, también tiene su lado contradictorio, ya que esta tecnología presenta una principal vulnerabilidad: la manipulación de los datos.
Qué es el Adversarial Machine Learning o ataques adversarios
Los investigadores y expertos se refieren a esta vulnerabilidad como “Adversarial Machine Learning (AML)” o ataques adversarios a la hora de abordar los riesgos de que los sistemas de inteligencia artificial puedan ser manipulados por adversarios de forma tal que realicen evaluaciones y predicciones incorrectas.
Agencias como NIST han comenzado a trabajar en recopilar el conjunto de terminología y taxonomía con el objetivo de informar los estándares futuros y las mejoras prácticas para evaluar y gestionar la seguridad de los componentes de ML mediante un lenguaje común y compresión sobre el panorama del AML.
El concepto de “Adversario” (del inglés Adversarial) es utilizado dentro del campo de la seguridad informática para denominar aquel sistema y/o cibercriminal que intenta atacar a un sistema con el objetivo de obtener un beneficio.
Existen algunos ejemplos de ataques adversos que podrían llevarse adelante a través de un modelo de ML con datos para que cometa errores, ya sea en la etapa de entrenamiento de ese modelo o incluso mediante la introducción de datos maliciosos específicamente diseñados para engañar a un modelo ya entrenado.
Cómo se lleva adelante un ataque adversario
El aprendizaje automático se centra en la capacidad de las computadoras para aprender de los datos proporcionados sin estar programados explícitamente para una tarea en particular, mientras que el aprendizaje automático adversario es el proceso de extraer información sobre el comportamiento y las características de un sistema de ML y/o aprender a manipular las entradas en un sistema de ML para obtener un resultado preferido. A grandes rasgos el AML puede funcionar de varias formas. Por ejemplo, podría emplear técnicas de ataque para afectar la precisión de los sistemas de aprendizaje automático manipulado algún aspecto.
Un atacante podría llegar a doblegar el sistema de ML para que tome la decisión incorrecta y el ataque puede suceder en diferentes etapas. Por ejemplo, en la etapa de inferencia, donde el atacante puede manipular las entradas (“perturbaciones de ruido”) para que el sistema de ML de una predicción de terreno. Para que quede más en claro, las perturbaciones son esencialmente cambios en los datos de entrada muy sutiles.
Estas “perturbaciones maliciosas” pueden ser ingresadas en diferentes fases del proceso de ML:
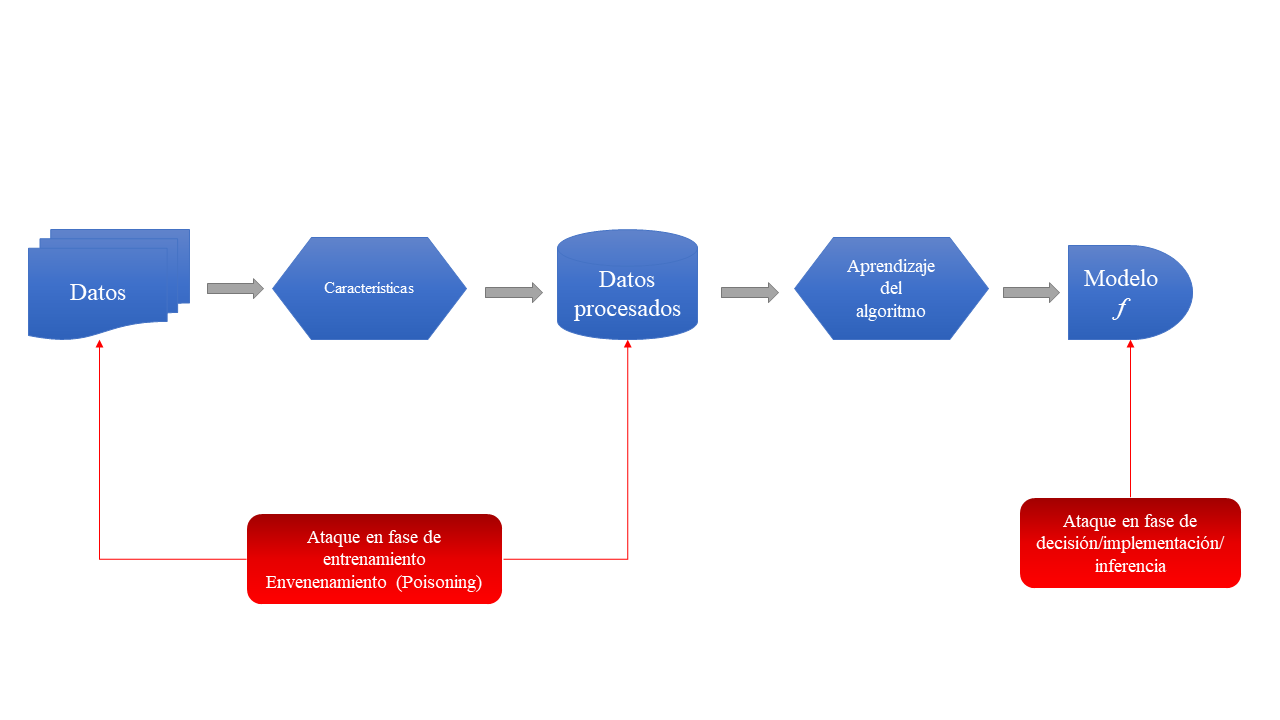
Categorías de ataque de ML según “Adversarial Machine Learning - Yevgeniy Vorobeychik & Murat Kantarcioglu”
Tipos de ataques adversarios que existen
Si pensamos el proceso de ML en dos etapas, tenemos el entrenamiento del modelo y luego su resultado, es decir, la fase de predicción, también conocida como etapa de inferencia. Esta última etapa se alcanza una vez obtenido el modelo, cuando le aportamos un nuevo set de datos y el ML ya entrenado debería “detectar” o hasta incluso “predecir”.
Por ejemplo, supongamos que queremos entrenar un modelo de ML para que detecte los archivos maliciosos según el nivel de entropía. Primero debemos ver qué modelo de ML es el que más se ajusta, por ejemplo Random Forest, Decision Tree, etc. Luego de entrenar el modelo y probarlo, cuando ingrese un archivo malicioso a través de la fase inferencia se bloqueará/detectará ese archivo.
Entendidas las dos principales fases, se desprenden los diferentes tipos de ataques que podrían tener los modelos de ML:
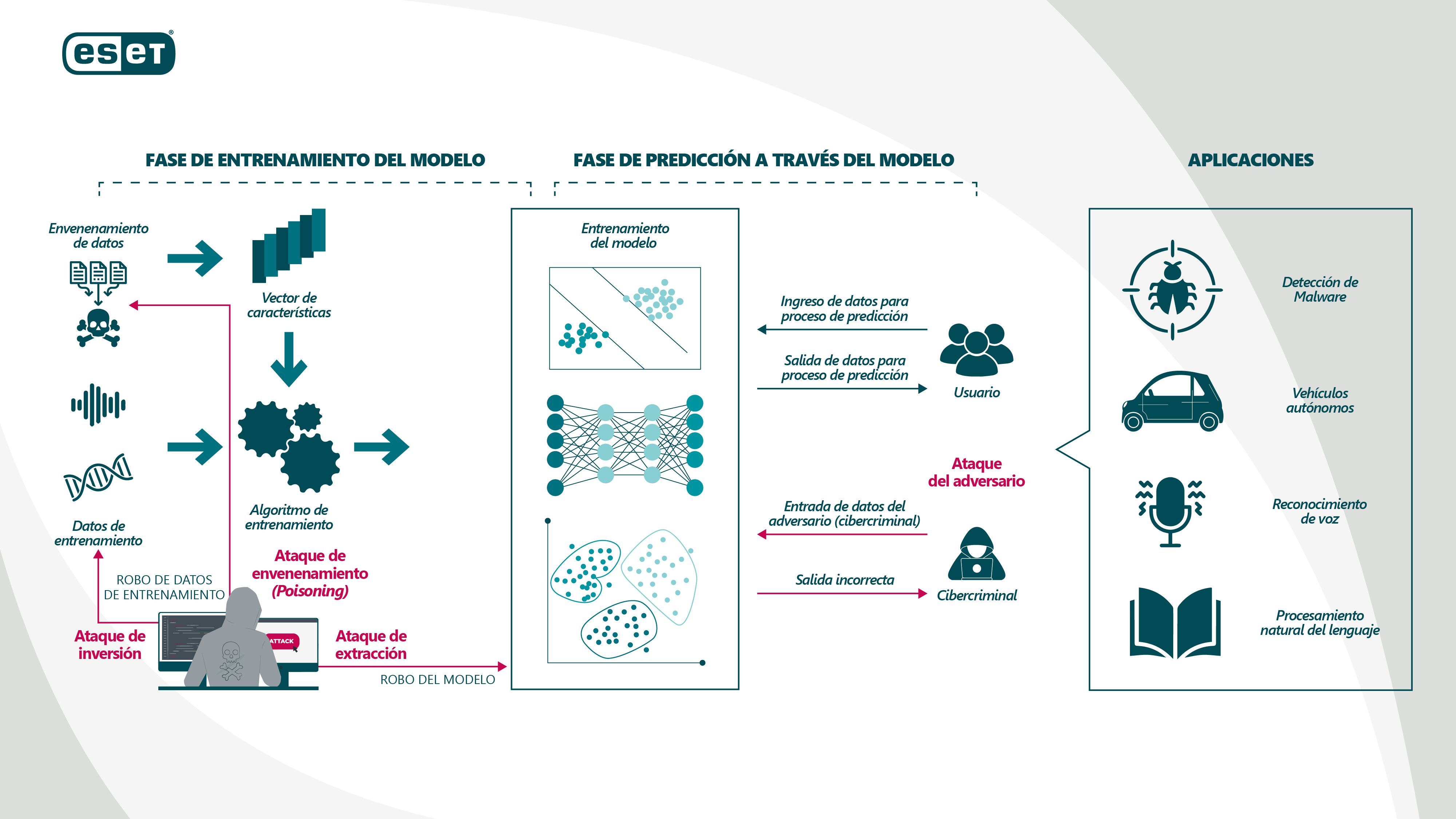
Tipos de ataques de ML - AML (Paper – “Towards Security of Deep Learning Systems: A Survey”)
Según el informe publicado por NIST, también se puede dividir a los a los ataques de AML según:
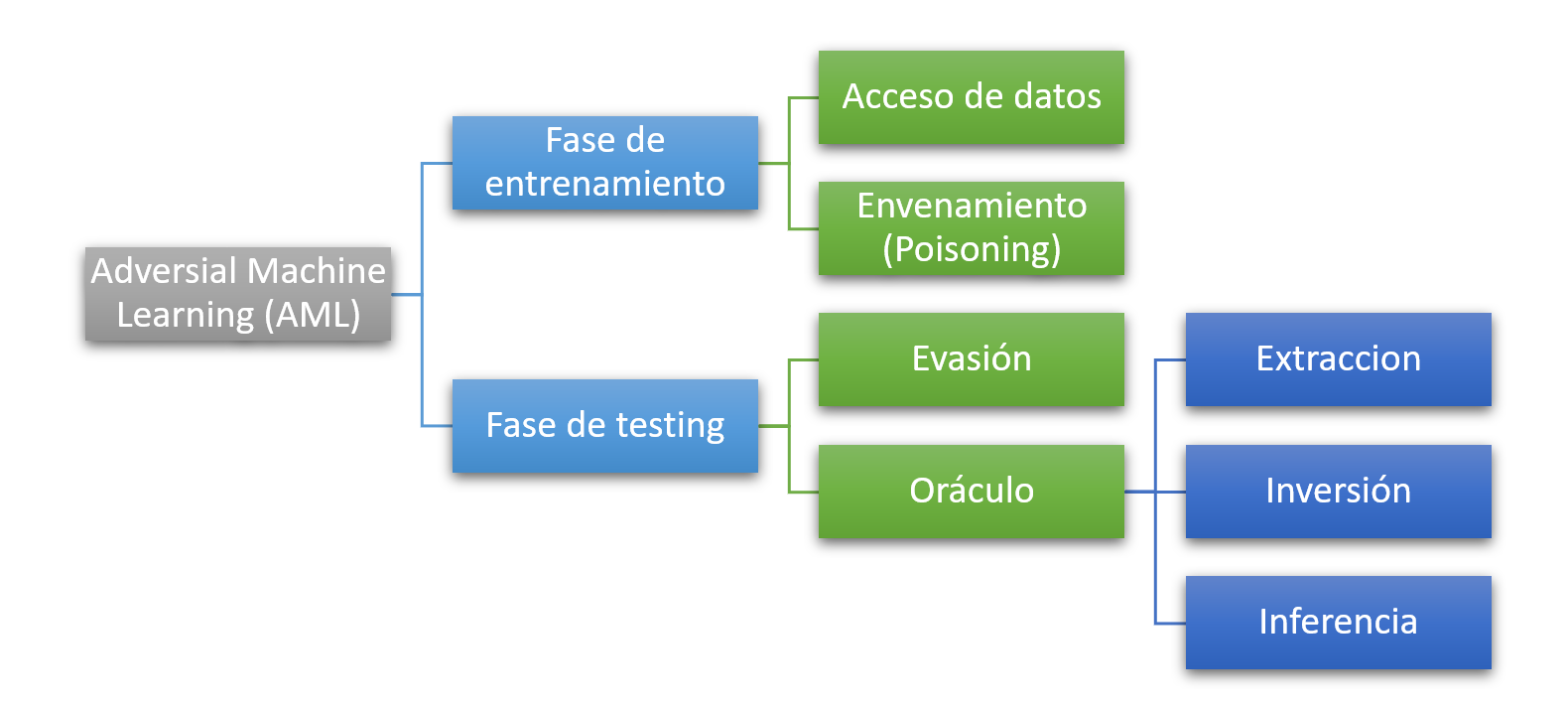
Clasificación de AML según NIST
A continuación se describen los principales ataques que podría sufrir un modelo de ML:
Ataques de envenenamiento (Poisoning)
Los ataques a los sistemas de ML durante la fase de entrenamiento son conocidos como ataques de “envenenamiento” o “contaminantes”. En estos casos, un adversario (cibercriminal) presenta datos etiquetados incorrectamente a un clasificador para que el sistema tome decisiones sesgadas o inexactas en el futuro. Los ataques de envenenamiento requieren que un adversario tenga cierto grado de control sobre los datos de entrenamiento.
También puede pasar que en el ataque de entrenamiento se proporcionen datos envenados (del inglés poisoning) para modificar el sistema de aprendizaje automático real. Es por esto que muchos investigadores catalogan este tipo de ataque como “ataque de backdoor”.
A través de este ataque el sistema de ML puede aprender un modelo incorrecto y pasar inadvertido, dado que para la mayoría de las entradas el sistema de aprendizaje automático dará la respuesta correcta. El problema ocurre si, por ejemplo, para ciertas entradas especificas elegidas por el cibercriminal y solo en estas situaciones, el sistema de aprendizaje dará una respuesta diseñada por el atacante. La gravedad de este tipo de ataque está en que es realmente muy sigiloso, porque para el Data Scientist a simple vista no es algo muy sencillo de detectar.
Pensemos en un ataque de este tipo que apunta a un sistema de reconocimiento facial. En este caso el atacante podría ajustar el modelo para que cierto tipos de rostros sean interpretados como los de una persona en particular para suplantar su identidad ante un sistema de reconocimiento facial y obtener acceso a determinada información. Acá es cuando incide los fallos gravemente de seguridad.
Ataque de evasión o exploratorios
A diferencia de los ataques de envenenamiento, los ataques de evasión se dan en la etapa de inferencia, también conocida como etapa de predicción. En este tipo de ataque los adversarios buscan inyectar datos con ruido para que el modelo realice la tarea de predicción de manera incorrecta.
Ataque de inversión
En el caso de los ataques de inversión las características inferidas pueden permitir al adversario reconstruir los datos utilizados para entrenar al modelo, incluida la información personal que viola la privacidad de un individuo. Estos ataques se diferencian de los anteriores, ya que su objetivo es acceder al modelo de ML, por ejemplo, conociendo los datos de entrenamiento o las propiedades que se utilizaron para entrenar el ML. Ahora bien, pensemos lo sensible que pueden ser ciertos datos que se generan en un hospital. Considerando que hoy en día se están utilizando los modelos de ML para predecir la detección de diagnóstico por imágenes, si se produce un ataque de este estilo pueden llegar a acceder a las historias clínicas de los pacientes.
Ataques de extracción
Según NIST, en los ataques de extracción un adversario extrae los parámetros o la estructura del modelo a partir de las observaciones de las predicciones del modelo; por lo general, incluidas las probabilidades devueltas para cada clase. Este tipo de ataque, además de robar la propiedad intelectual, también viola uno parámetros principales de la triada CID de la seguridad de la información, la confidencialidad. Además, este tipo de ataque habilita los ataques de evasión.
Si bien a grandes rasgos describimos la taxonomía principal de los ataques dirigidos a modelos de Machine Learning, la pregunta que muchos harán es ¿Existe una posibilidad de mitigar o prevenir estos ataques?
Defensa: cómo mitigar los ataques de adversarios en el ML
Los investigadores han estado ocupados tratando de abordar este problema y se han publicado varios artículos abordando esta temática.
Parte del gran desafío es que muchos de estos sistemas son cajas negras, ya que en general no es posible acceder a la lógica de procesamiento de estos modelos. Sin embargo, también es cierto que los cibercriminales solo necesitan encontrar una grieta en las defensas de un sistema para que se produzca un ataque adversario.
Si bien sigue siendo un tema complejo, en primera instancia muchos investigadores coinciden en adoptar un enfoque potencial para mejorar la solidez del ML. Es decir, generar una variedad de ataques contra un sistema con anticipación y capacitar al sistema para que aprenda cómo se vería un ataque adverso. De esta manera, haciendo analogía con la medicina, estaríamos construyendo un "sistema inmunológico" a este tipo de ataques. Si bien este enfoque tiene algunos beneficios, en general es insuficiente para detener todos los ataques, ya que el rango de posibles ataques es demasiado grande y no se puede generar con anticipación.
Otra forma de defensa posible radica en alterar continuamente los algoritmos que utiliza un modelo de aprendizaje automático para clasificar datos, es decir, crear un "objetivo en movimiento" manteniendo los algoritmos en secreto y cambiando el modelo de forma ocasional.
Como toda tecnología en auge, muchas veces el crecimiento exponencial no viene acompañado con el enfoque de ciberseguridad que se necesita. Por eso es importante que los desarrolladores de ML o Data Scientist sean conscientes de los riesgos potenciales asociados con estos sistemas para que pongan en marcha sistemas para la verificación cruzada y la verificación de la información. Otra forma podría es intentar romper con regularidad los propios modelos e identificar tantas debilidades potenciales como sea posible.
También podemos brindar defensas a través de herramientas de cifrado, mediante políticas de privacidad, entre otras formas. A continuación compartimos una ilustración sobre algunas recomendaciones:
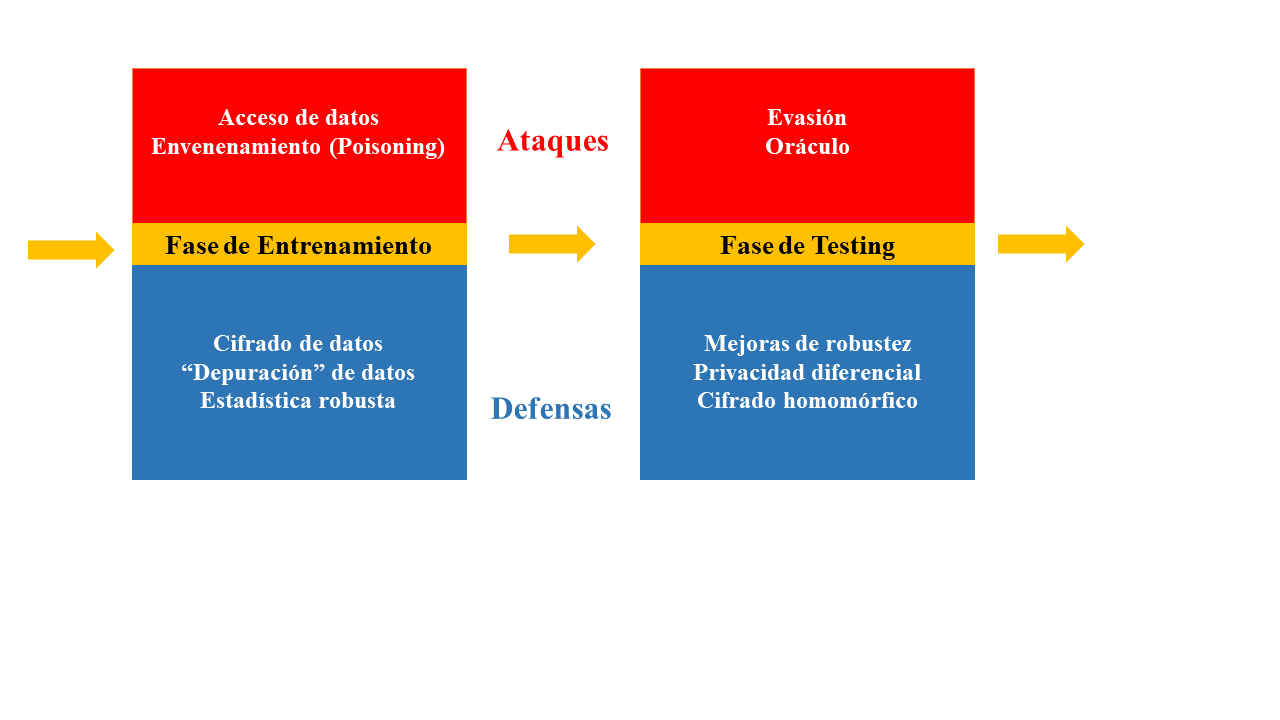
AML: Detalles de ataques y defensas NIST
MITRE ATLAS
Si el AML no fuese realmente un problema, muchas compañías no hubieran aportado sus conocimientos para el diseño de MITRE ATLAS. Es más, según un reporte publicado por Gartner en 2020 se estimaba que hasta 2022, el 30% de todos los ciberataques de IA aprovecharían el envenenamiento de datos de entrenamiento, el robo de modelos de IA o muestras adversas para atacar sistemas impulsados por IA.
Ya muchos conocen el modelo de MITRE ATTA&CK, el cual es una herramienta que sirve para para identificar las TTP (tácticas comunes, técnicas y procedimientos) que las amenazas persistentes avanzadas (APT) utilizan contra diversos sistemas. En cuanto a MITRE ATLAS, se trata de una herramienta creada en el año 2020 que brinda un panorama de amenazas adversas para sistemas de IA. En otras palabras, a través del modelo de MITRE ATLAS podemos observar las tácticas adversas y técnicas para sistemas de ML basados en observaciones del mundo real. Además, algo interesante que aporta este modelo es que posee demostraciones de ataque.
Como mencione anteriormente, la tecnología de ML se está utilizando cada vez más en diversas industrias, pero hace falta más conciencia sobre las vulnerabilidades que posee el ML. Dado que la superficie de ataque cada vez aumenta más, a través de la matriz de ATLAS se busca crear una base de conocimientos sobre las presentes amenazas para así facilitar a los investigadores de seguridad el conocimiento de esta tecnología en auge.
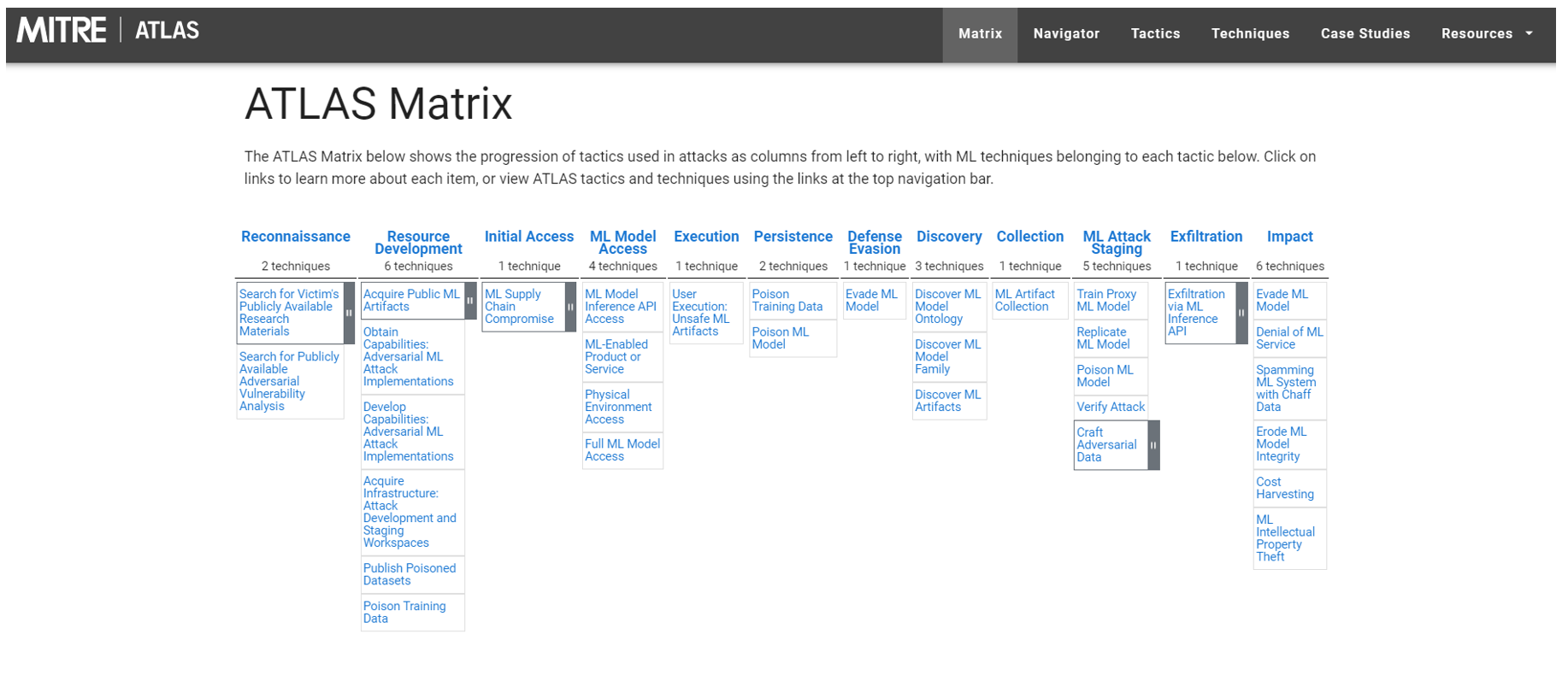
Imagen: MITRE ATLAS
Conclusión
Varios investigadores en ciberseguridad están preocupados por la posibilidad de que los ataques adversarios puedan convertirse en un problema grave en el futuro a medida que el aprendizaje automático se integre en una gama más amplia de sistemas, incluidos los automóviles autónomos y otras tecnologías.
Si bien este tipo de ataque todavía no es uno de los favoritos de los cibercriminales, no falta mucho para que lo sea; ya que la tecnología está avanzando rápidamente en el campo del ML. Por lo tanto, si no se empieza a detectar estas vulnerabilidades a tiempo podríamos encontrarnos con grandes problemas a futuro.
Para finalizar, les compartimos recursos externos para profundizar en este tema:



