

Con frecuencia escuchamos hablar de la necesidad de utilizar navegadores como Tor con el fin de preservar nuestra privacidad en línea o para evadir la censura en ciertas regiones del planeta. Sin embargo, no siempre resulta evidente la importancia que tiene la correcta gestión de nuestra privacidad en línea. Por eso, en este post explicaremos algunos conceptos básicos que pueden resultar de utilidad a la hora de administrar mejor nuestra privacidad en Internet, sobre todo cómo terceros pueden obtener información de nuestros dispositivos pese a navegar en modo incógnito o utilizando una VPN, y también hablaremos sobre el concepto de browser fingerprinting o huella digital del navegador, así como el rastreo de cookies.
Hay varias respuestas válidas a la pregunta de por qué debería importarnos la privacidad en línea y una de las razones más importantes es que la privacidad y la seguridad están relacionadas.
El concepto de privacidad en línea consiste en conservar fuera del alcance de terceros nuestra información personal o cualquier tipo de información que permita identificarnos y registrar nuestras actividades. Esta información puede ser útil para distintos fines. Los cibercriminales, por ejemplo, suelen emplear la recopilación de información de una víctima y utilizarla de distintas maneras.
Dicho esto, el foco de esta publicación estará puesto en información sobre nuestras actividades e intereses en Internet que permiten a un tercero tener una aproximación más o menos precisa de la persona que está detrás de una computadora, la cual puede ser utilizada tanto para determinar qué anuncios publicitarios se mostrarán a esa persona como para realizar prácticas de espionaje.
En este sentido, un actor malicioso podría llegar a utilizar la huella de nuestro navegador para averiguar qué complementos (plugins) tenemos instalados y explotar posibles vulnerabilidades que se presenten. No está demás aprovechar la ocasión para recordar que utilizar plugins desactualizados o de fuentes poco confiables aumenta significativamente nuestra superficie de ataque; además de hacer que nuestra huella digital sea más específica y, en consecuencia, más rastreable.
Métodos que pueden ser utilizados para rastrear a un usuario
Browser fingerprinting: la huella digital que deja tu navegador
Cuando accedemos a una página web, quienes la desarrollan pueden (y suelen) agregar scripts para obtener información de nuestro sistema operativo, adaptador gráfico, los formatos de audio soportados, la resolución de la pantalla, entre otros datos más.
El principal fin de esta información es el de optimizar el contenido del sitio para nuestro dispositivo.
El problema surge cuando nos conectamos a sitios poco confiables o bien, sitios confiables cuyos servidores hayan sido comprometidos por algún atacante, ya que puede ser utilizado como un método para recolectar información de la actividad por un actor malintencionado. En la siguiente imagen se puede ver un ejemplo de la información que puede ser recopilada por el servidor web.
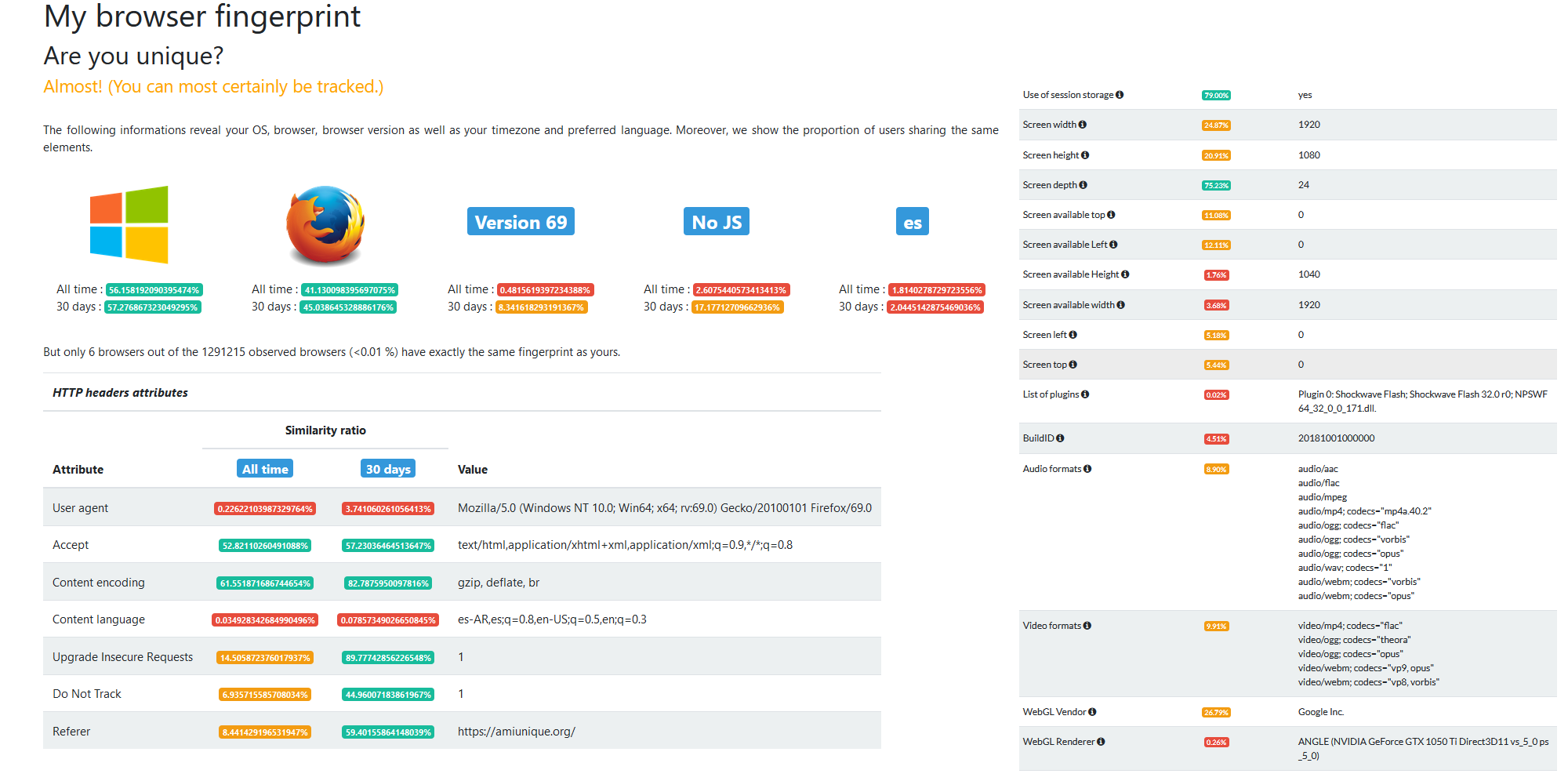
Ejemplo de datos que pueden obtenerse a partir de datos recopilados por el servidor web.
Quienes sepan inglés habrán notado que solo seis navegadores tienen exactamente el mismo fingerprint que el que fue utilizado para realizar esta demostración, entre aproximadamente 1,3 millones de configuraciones almacenadas en la base de datos. Esto permite una identificación con una precisión superior al 99.99%.
Otro método alternativo para obtener la huella de nuestro navegador es la utilización de Canvas, que es una API incluida por defecto en HTML5 (lenguaje utilizado por la mayoría de las páginas web) que permite utilizar Javascript para indicarle a nuestro navegador cómo debe crear un objeto gráfico y mostrarlo en la pantalla. El truco es que, dependiendo de las características de nuestro sistema, éste renderizado será levemente distinto al que realizarán la mayoría de los otros dispositivos, ya sea por utilizar diferente hardware, software o por distintas configuraciones. A partir de esto se puede generar un hash (función matemática) en base a nuestro sistema que será relativamente único y esto también permitirá la identificación con cierta precisión, como se ve en la siguiente imagen.
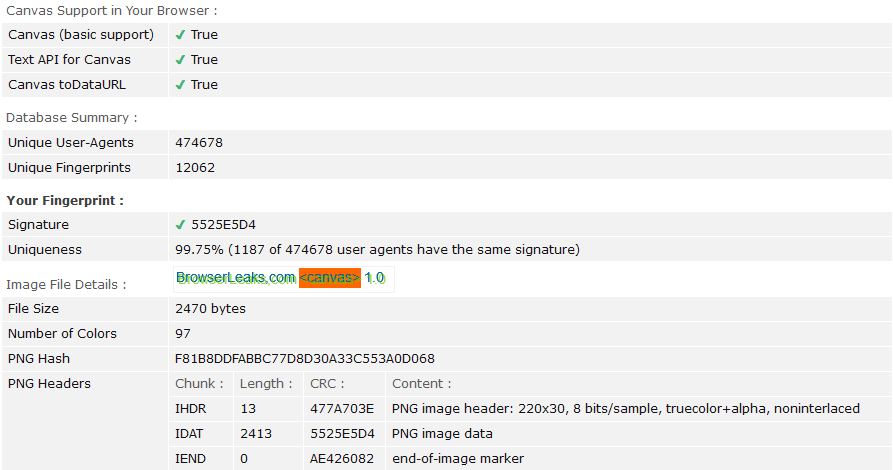
Información generada a partir de un hash en base a nuestro sistema
Este método es efectivo para rastrear usuarios en línea incluso cuando el uso de cookies esté deshabilitado, por ejemplo, cuando navegamos en “modo privado”. El uso de una VPN tampoco es útil contra estas prácticas.
Otros mecanismos más específicos que se pueden utilizar es comprobar en qué sitios el usuario ha iniciado sesión y qué librerías o tipografías específicas soporta el cliente.
Las Cookies y las Tracking Cookies
Una cookie es un archivo de texto que se guarda localmente en nuestra computadora al visitar una página web. Idealmente, su uso está limitado a mantener la sesión de usuario con el servidor (ya que el protocolo HTTP no posee esa funcionalidad) y guardar ciertas configuraciones, personalizaciones y preferencias. Son fundamentales para el uso de Internet como lo conocemos y pueden ayudar a mejorar la seguridad de nuestras credenciales.
Habiendo dicho esto, existen distintos tipos de cookies y cada una puede cumplir distintos fines. Además, es algo que muchas veces nos vemos forzados a aceptar sin consentimiento o información al respecto, en la mayoría de nuestros países (si entraron a algún sitio web europeo recientemente habrán notado que el sitio les pide aceptar la política de cookies ya que allí sí está regulado). Hoy nos vamos a concentrar en las Tracking Cookies, también conocidas como cookies de rastreo, un dolor de cabeza para quienes disfrutan de su privacidad en línea.
El uso de cookies está limitado al dominio que las emite bajo las reglas del Same Origin Policy que rige en Internet; es decir, una cookie emitida por abc.com solo puede ser leída y utilizada por abc.com. Bajo esta estricta teoría, debería ser imposible que una cookie “nos persiga” por Internet. Sin embargo, lo que ocurre es que, por diversos motivos, muchos sitios deciden alojar Cookies de Terceros en sus sitios; como puede ser la creación de estadísticas del tráfico web que reciben o para agregar una cierta funcionalidad a su sitio, como la posibilidad de usar el perfil de una red social para comentar en un foro.
Para hacer esto alojan un script desarollado en Javascript (si la acción se realiza del lado del cliente) o bien, utilizando iframes HTML o un "Tracking Pixel" (si se realiza desde el propio servidor), que efectivamente envía nuestra cookie emitida por abc.com a abc.com. Los dueños de abc.com ahora pueden saber quiénes somos, ya que solo nosotros tenemos la cookie emitida por el servidor y que sitio acabamos de visitar.
Las cookies pueden ser de sesión, es decir que se eliminarán al cerrar el navegador, o alternativamente pueden ser persistentes si el servidor especifica una fecha de caducidad.
Sin embargo, no todo son malas noticias. Algunos navegadores han comenzado este año a deshabilitar el uso de cookies de terceros por defecto, como es el caso de Mozilla.
Ejemplo de los scripts y cookies que se descargan al visitar, por ejemplo, la página web de un conocido diario.
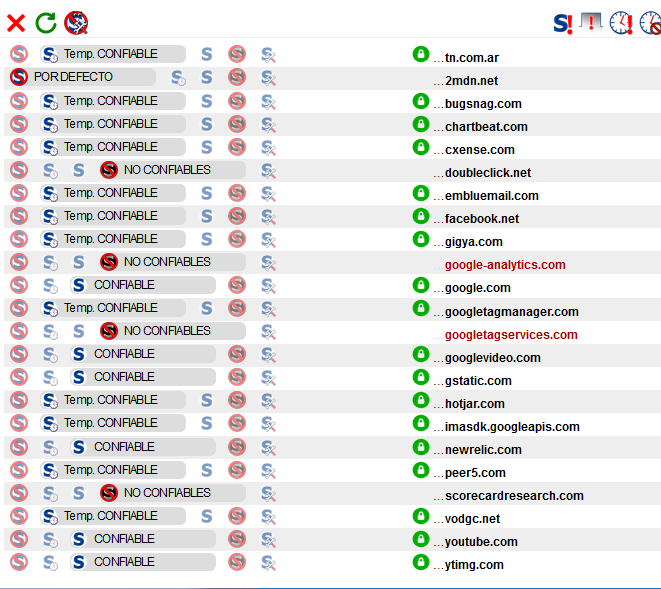
Complementos de un sitio promedio
WebRTC
Otra forma que puede ser utilizada por un tercero para obtener información del usuario a partir del navegador es mediante WebRTC, una API soportada y habilitada por defecto en todos los navegadores masivos. Permite al navegador interactuar en forma dinámica con el hardware de nuestro equipo, como micrófono o cámara web, además de algunos beneficios como la transferencia de archivos sin la necesidad de instalar plugins como Flash o Silverlight. Si bien está pensada para generar páginas con mayores funcionalidades, también permite obtener la dirección IP pública y privada del equipo (aun cuando se utiliza una VPN), obtener acceso al hardware y a los archivos en nuestro sistema.
Si bien la tecnología es prometedora, al mismo tiempo puede ser una preocupación más para los usuarios, ya que se han detectado numerosas vulnerabilidades graves, como la CVE-2016-10600.
Si no utilizamos este servicio, quizás sea una buena idea deshabilitarlo.
¿Qué puede hacer un tercero con esta información que dejamos en los sitios web?
Una empresa puede: optimizar el contenido del sitio para que funcione correctamente; personalizar el contenido de la página según nuestras preferencias; ofrecer publicidad u ofertas dirigidas a nuestros intereses; vender o compartir la información a terceros o acceder a cualquier cosa que hayamos aceptado en los términos y condiciones. Todo esto podría usarse para lograr una cierta ventaja competitiva.
Un atacante puede: obtener información de la configuración de nuestro sistema y utilizarla para realizar algún tipo de ataque; vender la información recopilada en la Deep Web, en sitios como Genesis Store, quizás junto con otra información que hayan recopilado (quizás pública). También pueden utilizar la información como un complemento para otro tipo de ataque.
Un investigador puede: vincular a una persona con un equipo físico desde el que se haya cometido un delito para generar una prueba utilizable en una corte.
Recomendaciones
Si después de leer este artículo estás interesado en mejorar tu privacidad y seguridad para tus actividades en línea, algunas recomendaciones (ordenadas según el grado de paranoia del usuario) pueden ser:
- No ingresar a sitios que sean potencialmente peligrosos o que hayan podido ser comprometidos. En este sentido, es muy recomendable la utilización de software antivirus que bloquee páginas web que realicen una actividad maliciosa.
- Mantener el navegador y sus extensiones actualizadas.
- No instalar complementos innecesarios o poco confiables.
- Configurar el navegador para no aceptar cookies de terceros, eliminar las que ya se encuentren guardadas.
- Utilizar complementos que bloqueen el uso de Javascript por defecto, solamente habilitar aquellos scripts en los cuales confiemos. NoScript es una opción para esto.
- Utilizar un Proxy confiable para nuestras conexiones o bien un navegador como Tor.
- Utilizar el sistema operativo Tails, que fuerza a que todas las conexiones a Internet se realicen a través de Tor.
Una de las funcionalidades de Tor es que nos permite aislar las cookies de cada sitio web de forma que nuestra actividad no pueda ser rastreada. Además, genera una “huella digital” falsa de nuestro navegador de forma que todos aquellos que utilizan Tor tengan huellas casi idénticas para evitar la identificación. Para más información, recomendamos la lectura del siguiente artículo: 3 opciones para navegar de forma anónima en Internet.
Conclusión
El conocimiento es poder, tanto para quienes buscan realizar malas acciones como para quienes buscan protegerse. La concientización sobre estas temáticas al menos permite un mayor control sobre qué compartimos y qué no.
Hay que recordar que ni la privacidad ni la seguridad total existe, salvo que vivamos debajo de una roca. Todos estos consejos pueden resultar inútiles si un sitio legítimo en el cual confiamos se ve comprometido por un atacante y se filtran sus datos. Lamentablemente, esto ya no está bajo nuestro control.
Teniendo en cuenta esto último, recomiendo la lectura del artículo “Cómo saber si la contraseña que utilizas fue filtrada en una brecha”, que explica cómo averiguar si tu información privada fue expuesta en una filtración que afectó a un sitio o servicio legítimo en el que quizás hayas creado una cuenta. Por último, recuerda cambiar tus contraseñas periódicamente.



