

Como iniciamos en el anterior artículo sobre visiones de un pentest, vamos a seguir con la serie dedicada a pequeños trucos a la hora de realizar una auditoría de seguridad.
Todas las recomendaciones que exponemos se pueden usar en el caso de que seas el que desempeña el rol de “atacante”, pero recuerda, se deben usar de manera defensiva, poniendo más difícil a un atacante su objetivo.
Vamos a proseguir en la serie con la segunda fase: el escaneo, en el que recopilamos en detalle la información de los sistemas a auditar. Hasta el momento, en la primera fase (reconocimiento) solo hemos hecho un perfilado de la organización con información más o menos pública, sin enviar mucha información al destino o incluso ninguna.
¿Cómo empezamos a recolectar información?
En los subdominios encontramos fallos, ya que los administradores prestan atención a los sistemas principales y olvidan los de poco uso
Mi proceso de auditoría suele comenzar con una enumeración más en detalle del destino, realizando la típica transferencia de zona al servidor DNS. Esto consiste en preguntar al servidor DNS de la organización por todos (absolutamente todos) los registros disponibles. Si el servidor está bien configurado no nos responderá, solo tendrá permiso para responder a otro servidor DNS de la organización autorizado. En muchas ocasiones el administrador configura mal esta réplica, permitiendo al atacante la mencionada transferencia de zona.
Hay mil y un manuales en la red que explican cómo realizar la petición mediante nslookup en Windows, o Dig en Linux, pero la comodidad me indica que mejor usar servicios públicos y gratuitos como el que ofrece Hacker Target.
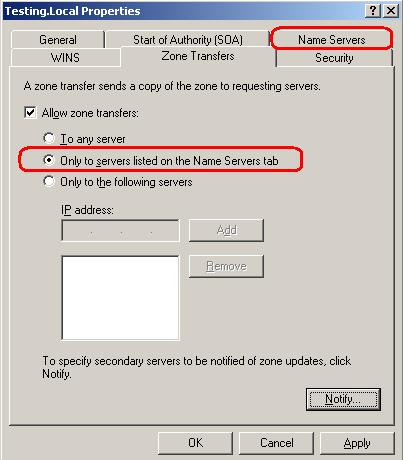
Por ejemplo, cuando en una organización tenemos al menos dos servidores Active Directory con DNS, automáticamente se configura una replicación de zona, una transferencia de zona que permite que los registros existan en los dos servidores. Si uno de ellos cae, el otro tiene la información de la zona. Este es un ejemplo de cómo configurar qué servidores pueden replicarse y no dejarlo librado a que sea cualquiera:
Si todo ha ido bien, podemos obtener los registros DNS de una empresa, por ejemplo los típicos webmail.empresa.com, test.empresa.com, interno.empresa.com, asistencia.empresa.com. Buscamos toda la información disponible, y por mi experiencia os puedo contar que en todos estos subdominios es donde encontramos los fallos, ya que los administradores suelen (o no) prestar atención en los sistemas principales (el sitio web de la empresa, el correo) pero dejan olvidados pequeños sistemas de poco uso o que mantienen otras empresas. ¡Ahí es donde más duele!
Fingerprint: tras las huellas de los sistemas
El siguiente pequeño consejo es realizar un fingerprint correcto de cada sistema. Fingerprint es la huella que dejan los sistemas y que identifica su marca, modelo, versión, etc. Por ejemplo, un servidor Apache, un servidor FTP Filezilla, un equipo Windows 2008 o cualquier sistema que exponga un puerto de red. Lo básico en este punto es comprobar el banner y el mensaje de conexión del sistema, pero también realizar comprobaciones para detectar si se ha hecho un trabajo de “anti-fingerprint” con el fin de ponernos más difícil el trabajo.
Para los servidores web suelo emplear varias comprobaciones, por ejemplo una herramienta denominada httprint o el servicio online HTTPRecon. No te dejes engatusar por el banner que ofrece el servidor al realizar peticiones “raras” o el Nmap –sV; comprueba siempre qué sistema hay detrás.

Las cosas no siempre son lo que parecen
Hay casos más complejos en los que el servicio no ofrece ningún mensaje o banner, y debemos realizar otro tipo de aproximaciones para detectar qué sistema hay a la escucha. Algo muy habitual es realizar una captura de red antes de realizar una petición. Para ello, realizamos una petición manual al puerto mediante la herramienta Telnet o Netcat y analizamos la información obtenida.
Puede que no aparezca información “humana” como banner del servicio, pero a nivel de red hay sistemas que se identifican, como puede ser una negociación de claves privadas en una conexión IPSEC o mil protocolos más.
¿Y si estamos ante sistemas de gestión de contenidos?
Siguiendo la tendencia de los CMS (Content Management Services) como Wordpress o Joomla, averiguar si la aplicación web que vamos a auditar se basa en uno de estos sistemas es otra tarea habitual. Estas aplicaciones suelen tener un fingerprint muy característico, desde el banner, ficheros Readme.html, hasta maneras de montar las URL como /wp-admin/ o /administrator/. Estas pequeñas diferencias identifican claramente la aplicación y muchas veces la versión.
he visto todo tipo de trabajos mal hechos en programación, que hacen posible el éxito en el pentesting
El consejo defensivo en este sentido es el de usar técnicas anti-fingerprint basadas en plugins de seguridad para nuestros CMS. Recuerda que la Web suele ser de lo más atacado. Una de las aplicaciones más usadas para descubrimiento automático de vulnerabilidades en estos sistemas es JOOMSCAN para Joomla y WPSCAN para Wordpress.
Por supuesto que para las aplicaciones web debemos realizar la tarea de “spider” o araña. Esta técnica recolecta todas las direcciones y peticiones de la web, armando lo que sería un mapa web. Muchas aplicaciones nos los ofrecen en la parte inferior del sitio.
Una vez que tenemos la estructura completa del sitio, se suele usar un proxy como Burp Suite o ZAP. Como sabes, las direcciones y peticiones web se pueden realizar mediante GET o POST. En el primer caso la URL completa aparece en el navegador, mientras que si usamos POST la petición no aparece. Pongamos estos dos ejemplos.
- POST: http://www.miempresa.com/login.php
- GET: http://www.miempresa.com/login.php?user=kino&password=makino
Puede que sea la petición que hace una aplicación web que nos pide usuario y contraseña. La diferencia es que la de arriba es POST y no muestra los valores y la de abajo es GET y sí los muestra. Es muy útil ver esta información para “manipular” los valores, pero si la petición es POST no los vemos. Para eso se configura en el navegador el proxy intermedio y tenemos un programa que intercepta las peticiones desde nuestro navegador, antes de llegar al servidor.
Aquí se nos abre un mundo de posibilidades ya que tenemos las peticiones de manera clara y quizás el programador no haya contado con este detalle (que podemos ver todo este tráfico de información). A lo largo de mi carrera he visto todo tipo de trabajos mal hechos en la programación, que hacen posible el éxito en el pentesting. Una fácil: usar un campo oculto para un producto en una tienda online. Como vemos la petición, podemos manipular el valor del producto; el servidor confía en lo que se ha enviado, y podemos comprar por un precio que establecemos nosotros. Bueno, no queremos dar más pistas al respecto…
Creo que con esta serie de consejos básicos podéis continuar con vuestros procesos de pentesting a vuestros sistemas, o al menos os servirá de ayuda a la hora de plantear una defensa en profundidad. En el siguiente capítulo seguiremos con más consejos para las siguientes fases de la auditoría: enumeración, acceso y mantenimiento de acceso.
Sigue leyendo: ¿En qué consiste un penetration test?



