

Cuando realizamos reversing sobre una posible amenaza tenemos que acostumbrarnos a la idea de que vamos a revisar cientos de líneas de código en un lenguaje de bajo nivel, tan solo para comprender una parte del funcionamiento. Esto puede sonar fatal y desanimar a aquellos que se están iniciando; después de todo, a mí me ocurrió cuando empecé a aprenderlo. Sin embargo, uno no tarda en darse cuenta que con un poco de práctica y las herramientas adecuadas, la ingeniería reversa no tiene por qué ser una experiencia desagradable. Por ello, en este post compartiremos una introducción a ciertos patrones que suelen verse al realizar reversing en arquitecturas x86, lo cual nos permitirá ubicarnos rápidamente y comprender mejor el código.
Ya hemos tratado en este blog las bases del análisis estático de malware, y sabemos cuán importante resulta el reversing dentro de las actividades necesarias para el análisis de códigos maliciosos. Además, hemos analizado las instrucciones, registros y operadores en x86, lo que constituye un cuerpo de conocimientos necesarios para comenzar a realizar ingeniería reversa. Sin embargo, imaginemos que ha llegado el momento de desensamblar un archivo ejecutable. ¿Ahora qué hacemos? Conocemos las instrucciones, pero… ¿empezamos a leer cada línea secuencialmente, interpretando lo que hace cada instrucción?
Si bien en algún momento de nuestro análisis seguramente tendremos que inspeccionar una porción del código que nos interesa línea por línea, también es cierto que existen muchas herramientas que nos facilitan enormemente la tarea de encontrar aquello que queremos en un momento determinado. Después de todo, ¡divide y vencerás!
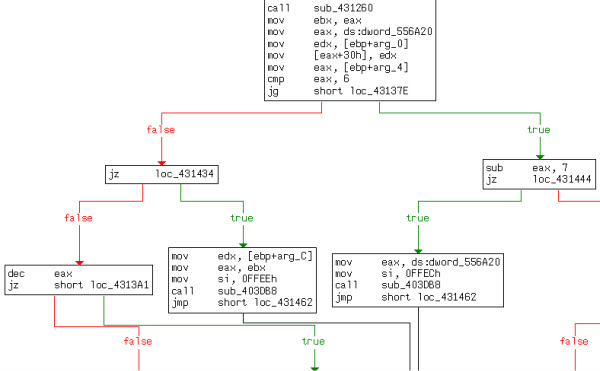
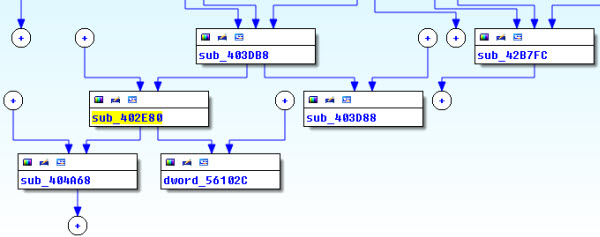
En la imagen anterior vemos cómo un desensamblador (IDA, en este caso) no solo nos muestra el código, sino que además nos estructura el flujo de ejecución de forma gráfica. De esta forma, resulta mucho más sencillo seguir los saltos condicionales y los posibles escenarios de ejecución dentro de una subrutina. Adicionalmente, puede accederse a un diagrama con la interconexión y jerarquía de las diversas funciones o subrutinas en el ejecutable. Esto se observa en la imagen a continuación:
Pero más allá de todas las facilidades que brindan las herramientas, hay ciertas situaciones que se repiten en la ingeniería reversa y que vale la pena destacar. Para comenzar, analizaremos el siguiente programa:

Puede observarse que es muy sencillo: el programa recibe un argumento que se almacena como número entero en una variable local y se llama a la subrutina sub con esa variable local y el conteo de argumentos en argc. Esta subrutina simplemente retorna la suma de esos dos valores. Al desensamblar el ejecutable producido por estas líneas de código, se obtiene lo siguiente:

En color rojo se marcan unas líneas que aparecen al inicio de cada rutina (main y sub) y que en general deberíamos encontrar al inicio de cualquier rutina, ya que realizan tareas de inicialización de la sección de la pila o stack correspondiente. Cuando main invoca a sub, sub debe realizar el cambio de la sección del stack de main a la sección propia de sub, guardando el valor base de main para poder restablecerlo luego; este hecho se traduce en push ebp. Luego, mov ebp, esp realiza el cambio a la sección del stack de sub. También con color rojo se marcan las líneas que invierten ese proceso una vez que la rutina ha terminado de ejecutarse: mov esp, ebp retrocede el stack pointer hasta la base, limpiando así las variables locales o cualquier otro dato innecesario que haya quedado en la pila; mientras que pop ebp restablece el puntero base a la rutina previa. Se observa que sub sólo incluye pop ebp dado que no cuenta con variables locales u otros datos que limpiar del stack. En definitiva, si vemos estas instrucciones ahora, podemos saber dónde empieza y termina una rutina, y nos resultará particularmente útil si en algún momento nos perdemos en el código.
Por último, cabe destacar que en la imagen se han resaltado distintos patrones con otros colores, que están relacionados con limpieza del stack, convenciones de llamadas a subrutinas, asignación de espacio para variables locales y manipulación de parámetros y variables. No obstante, cubriremos estas cuestiones, y otras, en la segunda parte de este post, ¡de modo que los esperamos en "Reconociendo estructuras comunes en ingeniería reversa parte II"!



