

Ssdeep y sdhash son dos algoritmos de fuzzy hashing que nos permite saber que tan similares son dos o más archivos, en este post veremos las características principales y la forma de utilizarlos.
Para determinar si dos archivos son iguales suelen utilizarse herramientas como MD5, SHA1, SHA256, entre otros. Pero si quisiéramos saber además que tan parecidos son y no solamente si son iguales o diferentes, podemos utilizar herramientas de fuzzy hashing como ssdeep o sdhash.
Ambos algoritmos arrojan como resultado un número que representa el porcentaje de similitud de dos archivos, claro que la forma de calcularlo es bastante diferente.
Comparando archivos con ssdeep
Uno de los algoritmos de fuzzy hashing más conocido es ssdeep. Esta herramienta fue publicada en 2006 como una alternativa a las técnicas hashing criptográfico como MD5 o SHA1 para determinar entre dos archivos cual es el porcentaje de similitud.
El algoritmo de ssdeep divide de forma secuencial un archivo en grupos iguales de bytes, y sobre cada uno de estos grupos calcula un hash. Luego a partir de estos se calcula un nuevo hash que va a representar el total del archivo. Y es precisamente sobre este hash que se puede comparar la similitud con otros archivos.
El siguiente script en Python nos puede ayudar a comparar varios archivos entre si:
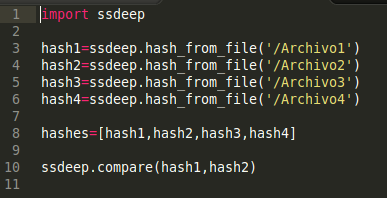
Si analizamos las diferentes variables podremos ver cómo quedan construidos los hashes de cada archivo y tener una idea de las partes de los archivos que son diferentes:

En el caso anterior, vemos como al comparar varios archivos se puede tener una idea de en qué porciones de código dos archivos son diferentes. Por ejemplo entre los archivos 1 y 2 las diferencias se encuentran al inicio del archivo, entre el 2 y el 3 las diferencias están al final del mismo. Mientras que entre el archivo 3 y 4 hay diferencias a lo largo de todo el archivo.
sdhash una mejora para comparar binarios
Otro algoritmo utilizado para determinar la similitud entre varios archivos es sdhash. Este algoritmo planteado en 2010, hace un análisis probabilístico para encontrar las características dentro del código del archivo que tienen más baja de probabilidad de ocurrir al azar. Los hashes de estas porciones de códigos pasan por un filtro de Bloom y sobre sus resultados utilizando la distancia de Hamming para determinar que tan diferente es un archivo de otro.
Si bien este algoritmo es más complejo en su concepción, resulta dar resultados mucho mejores que ssdeep al momento de comparar muestras de malware, pues no hace un barrido secuencial del código sino un análisis estadístico de mismo.
Aún así es igualmente sencillo de utilizar y nos arroja como resultado un valor que indica el grado de similitud entre los archivos. Después de descargar e instalar la librería de sdhash, bastan dos líneas para generar calcular los hashes y comparar un grupo de archivos que tengamos en una carpeta, simplemente basta con definir el umbral a partir del cual queremos que se almacenen los resultados:

Si analizamos los hashes generados por esta herramienta, podremos ver que son bastantes diferentes de los generados por ssdeep ya que son mucho más extensos y complejos:

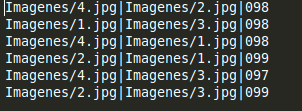
La salida de sdhash después de comparar los diferentes hashes es un conjunto de 3-tuplas con los nombres de los archivos y el porcentaje de similitud entre ellos:
Con los resultados arrojados por estos algoritmos, resulta factible hacer un análisis a partir de la teoría de grafos. En un próximo post veremos como a partir de esta información podríamos determinar si en un conjunto grande de muestras hay relaciones entre grupos de archivos.



