

Un tipo de lenguaje de programación muy utilizado por desarrolladores de malware, grupos cibercriminales o grupos APT, es el C++, una extensión del lenguaje en C que permite la creación y manipulación de clases y habilita a la programación orientada a objetos (POO).
Analizar un código malicioso desarrollado en este lenguaje puede terminar siendo una tarea muy extensa, por ello, vamos a dar unos tips que podrán ser de ayuda al momento de analizar una muestra de malware. Será una introducción para aquellas personas que analizan malware en C++ por primera vez.
Primeros pasos
Primero vamos a crear un programa sencillo en C++ con dos clases, luego vamos a compilarlo para obtener un archivo ejecutable. Usando la herramienta IDA Free, podremos comparar el código fuente del programa con el pseudocódigo que nos generará la herramienta.
De esta forma analizaremos similitudes entre ambos, diferencias y aprenderemos a detectar objetos y a crear una estructura que sea representada por ese objeto.
Por último, pasaremos a ver otro ejemplo que será sobre una muestra de malware.
Conceptos básicos de POO
Antes de continuar, repasemos qué es un objeto y qué es una clase en programación orientada a objetos.
· Objeto: Instancia de una clase, ente que consta de un estado y de un comportamiento.
· Clase: Conjunto de variables y métodos apropiados para operar con dichos datos.
1. Primer ejemplo: algo sencillo
El siguiente código de ejemplo va a constar de dos clases llamadas Vaca y Pato las cuales poseen variables y métodos. A su vez vamos a contar con método main donde vamos a crear objetos de esas clases y los procederemos a utilizar.
Luego compilaremos este código de ejemplo para tener un archivo ejecutable que vamos a ver después con el IDA Free y dentro del IDA veremos como reconstruir estas clases en lo que se denomina estructuras.
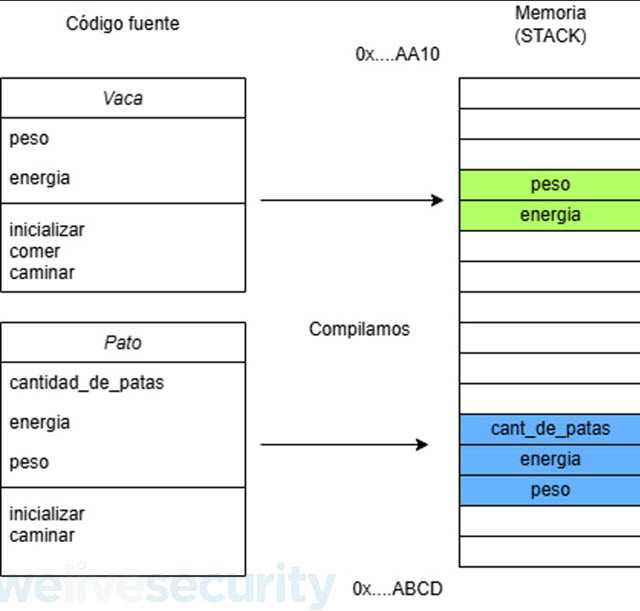
Las siguientes capturas de pantalla muestran el código fuente de nuestras clases y la lógica del método main de nuestro ejemplo.
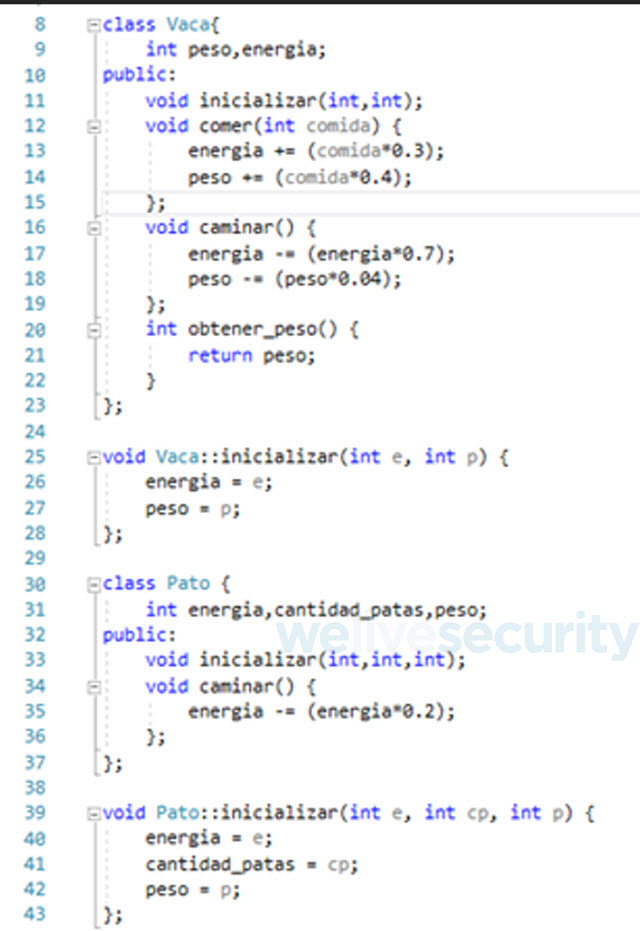
Compilación y análisis con IDA Free
A continuación, procederemos a compilar este ejemplo y generar un archivo binario para poder verlo con IDA Free.
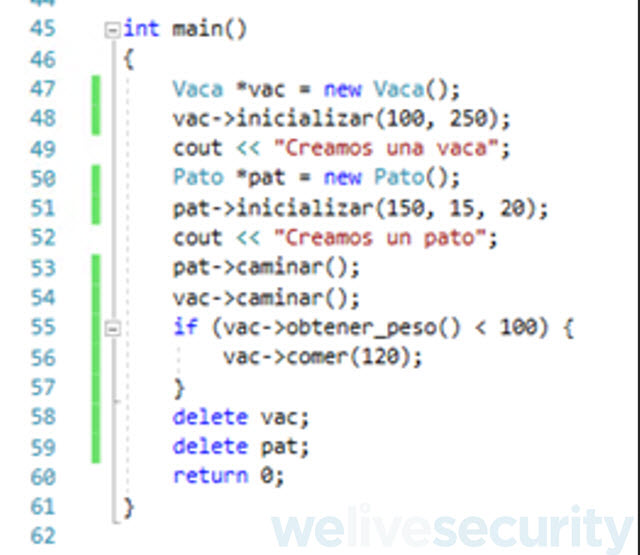
La siguiente captura de pantalla muestra el código de compilado del método main por IDA Free de nuestro ejemplo.
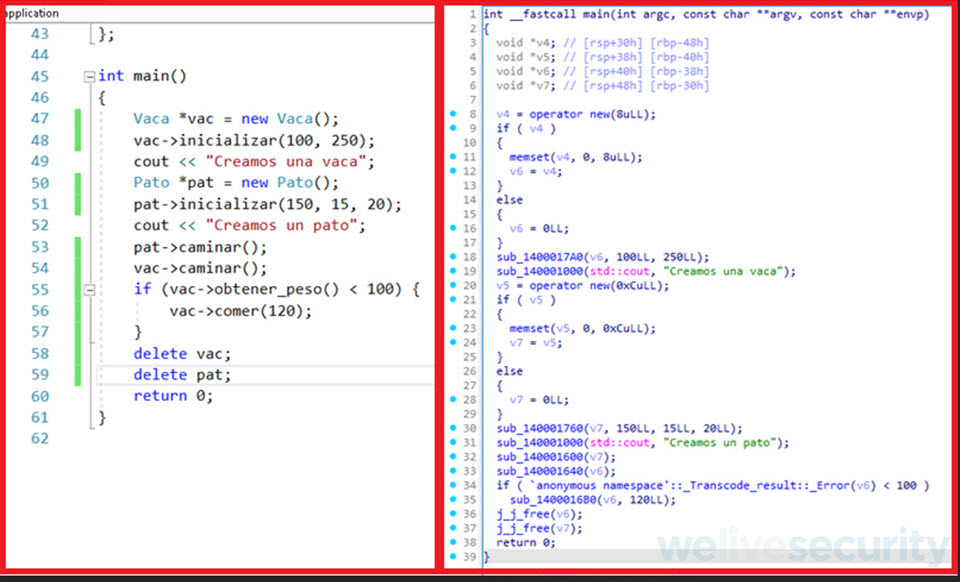
La siguiente captura de pantalla nos muestra a la izquierda el código fuente de nuestro ejemplo y a la derecha el código pseudocódigo generado por el decompilador de IDA Free.
Interpretación del código compilado
De la ilustración anterior podemos ver que cuando nuestro código C++ es compilado, IDA Free interpreta los métodos como subrutinas en una determinada posición de memoria del archivo ejecutable, estas subrutinas empiezan con el prefijo “sub_”, ejemplo sub_140001760.
A su vez, IDA posee una caracteristica para detectar funciones que pertenezcan a librerías conocidas o APIs de Windows y les da un nombre especifico en vez de uno genérico (sub_XXXXXX), por ejemplo, en el recuadro de la derecha de la ilustración en las líneas 36 y 37 IDA detecto la función encargada de eliminar un objeto de la memoria y la renombra como “j_j_free”.
Pérdida de expresividad en la compilación
Ahora bien, al compilar un código con clases y objetos, el concepto de clase con sus atributos y métodos se pierde, donde los atributos van a pasar a ser posiciones en memoria donde alojaran en respectivo valor del atributo. Y la expresividad de ambos también se pierde, por ejemplo donde teníamos pat = new Pato(); ahora pasamos a tener v5 = operator new (0xC) .
La siguiente captura de pantalla muestra lo que ocurre con los atributos de nuestra clase al momento de compilar un código fuente.
Siguiendo el código decompilado del método main en la Ilustración 3, lo primero que vemos es la creación de un objeto por medio del método operator new, que para ello le va a asignar 8 bytes de memoria. Si comparamos eso con nuestro código fuente, esta es la interpretación que hace IDA Free de la creación de nuestro objeto vaca cuando fue creado en nuestro código fuente.
Análisis del método inicializar
Ahora pasemos a ver qué ocurre con el método inicializar de nuestra clase Vaca, que es la subrutina sub_1400017A0 visto desde el decompilador.
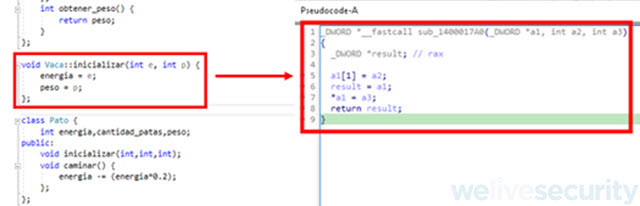
Por un lado, si vemos la subrutina decompilada, sub_1400017A0, recibe por parámetro una variable extra _DWORD *a1. Esta variable es el objeto de nuestra clase vaca a la cual se le van a cargar los valores de energía y peso sobre sus respectivos atributos.
Ahora si prestamos atención al código decompilado puntualmente en las líneas 5 y 7 vemos que IDA trata a nuestro objeto como un array, cargándole valores en una determinada posición. Esto ocurre porque IDA no sabe que en realidad se trata de un objeto perteneciente a una clase, como dijimos antes el concepto de clase se pierde cuando se compila el código fuente y nuestras variables o atributos pasan a ser posiciones en memoria de las cuales nosotros tenemos que indicarle al decompilador que en realidad se trata del objeto de una clase.
Creación de estructura Vaca
Para poder indicarle a IDA Free que trate a este array como el objeto de una clase, tenemos que crear una estructura que represente a la clase Vaca. Para ello, posicionados sobre IDA Free vamos a pulsar las teclas SHIFT+F1 para ver habilitar la pestaña de Local Types la cual utilizaremos para crear nuestra estructura.
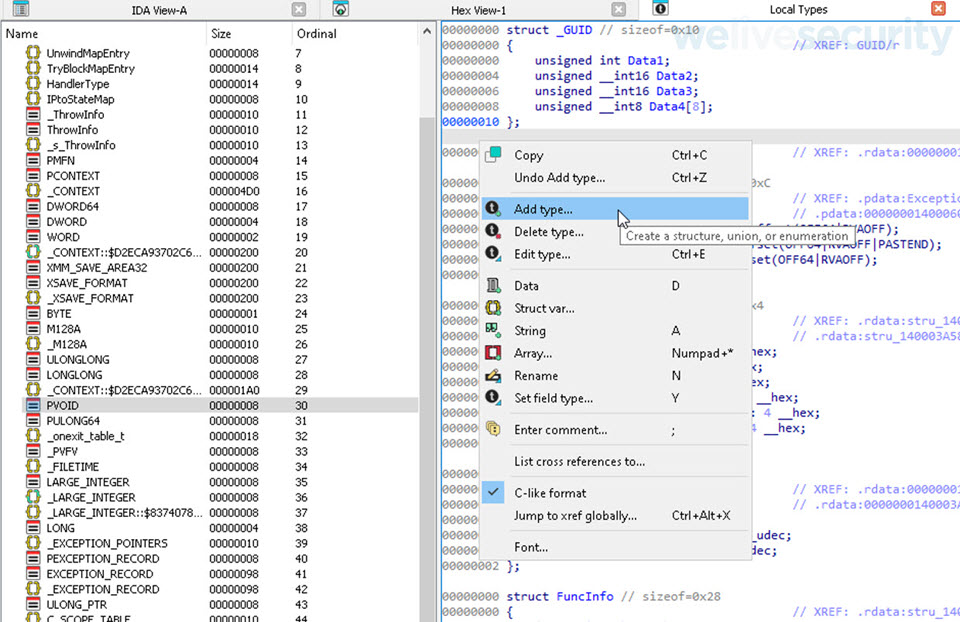
ACLARACION: En versiones anteriores, IDA Free o IDA Freeware posee una vista solo de estructuras la cual puede acceder pulsando las teclas SHIFT+F9.
Dentro de la vista Local Types vamos a agregar un nuevo tipo, para ello dentro de la vista haremos clic al botón derecho del mouse -> Add type…
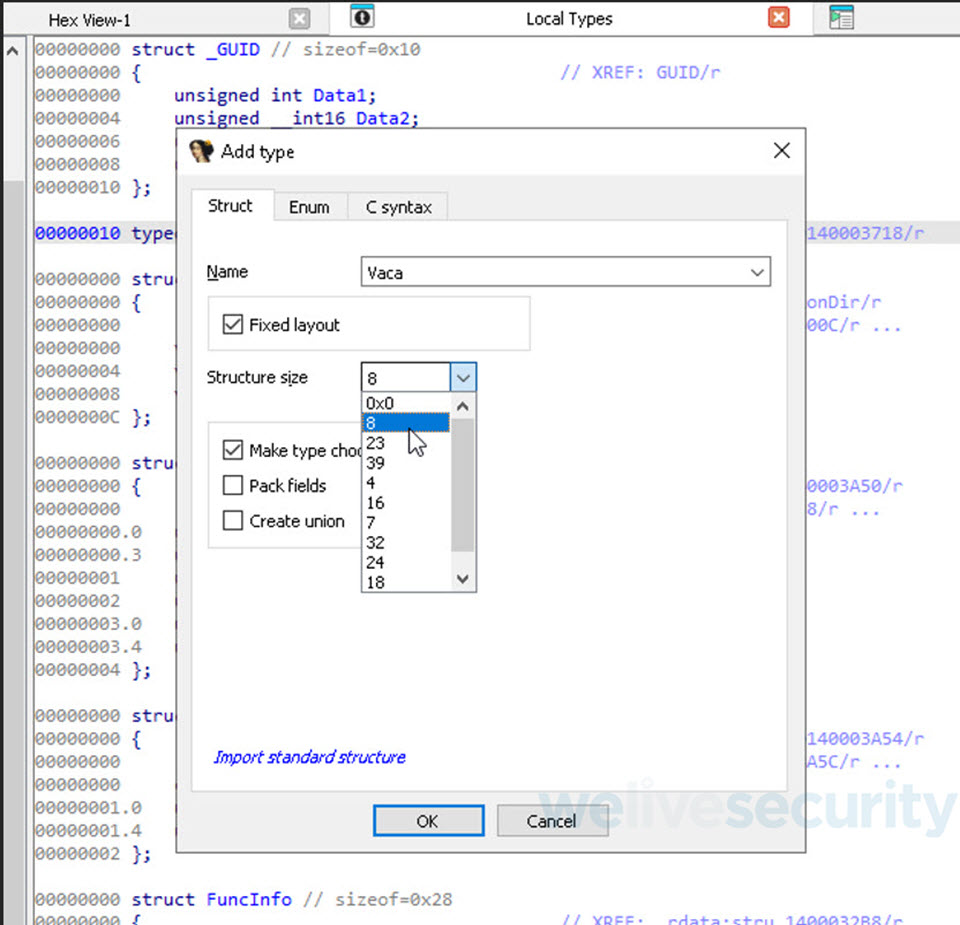
La estructura la vamos a crear con un tamaño de 8 bytes. Esto lo podemos inferir porque tenemos dos variables del tipo int dentro de la clase Vaca de las cuales utiliza 4 bytes para el valor del peso y las otras cuatro restantes para la energía. A su vez, recordemos que el binario cuando crea el objeto Vaca por medio del método operator new lo crea con un tamaño de 8 bytes. Estos 8 bytes son utilizados para las variables ya que los métodos de las clases terminan siendo subrutinas declarada dentro del código cuando son llamadas.
Una vez creada nuestra estructura, nos falta asignarle los datos del tipo a nuestras variables, que en este caso se trata del tipo de dato int el cual se representa con 4 bytes. Para ello nos posicionamos dentro de la estructura y apretaremos la tecla “d” hasta que tengamos un tipo de dato de 4 bytes que representa el peso, luego repetimos el proceso hasta que tengamos el otro dato que representa la energía de nuestra vaca.
Las siguientes capturas de pantalla muestran la estructura vaca creada sin variables y luego con sus respectivas variables declaradas.
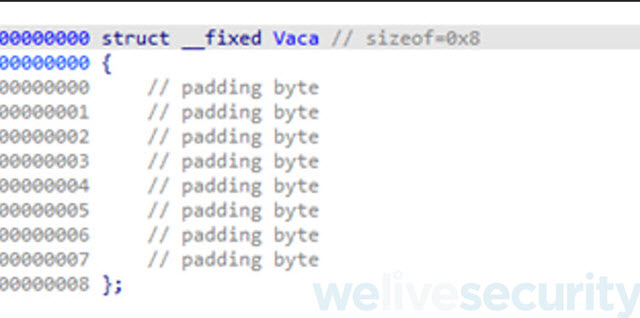
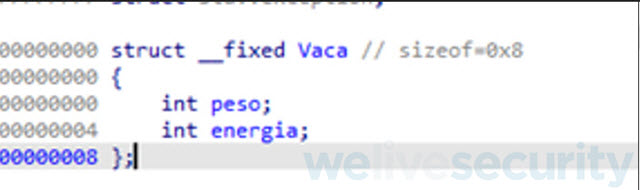
ACLARACION: Cuando IDA Free crea variables dentro de una estructura les asigna el prefijo field_ y un número. Para cambiar ese nombre basta con pararse sobre la variable apretar la tecla “n” y renombrarla por el nombre que se desee.
Reemplazo de tipos de datos en la subrutina
Ahora que ya tenemos nuestra estructura creada, nos falta reemplazar en la subrutina de inicialización de la Vaca el tipo de dato de la variable a1 que por defecto IDA la puso como tipo _DWORD. Para ello, nos posicionamos sobre el tipo de dato de a1 dentro de la declaración de la subrutina y con la tecla “y” vamos a poder editar la declaración de la variable que de _DWORD *a1 va a pasar a ser Vaca *mi_vaca.
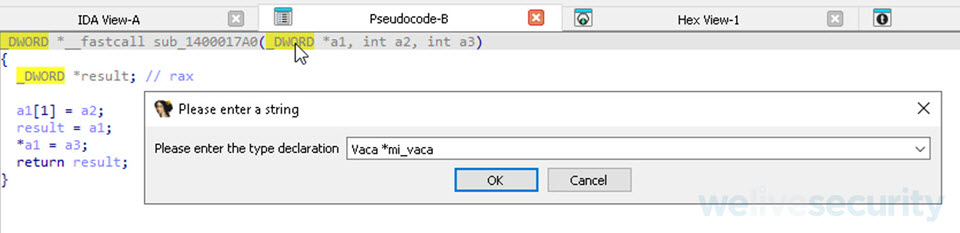
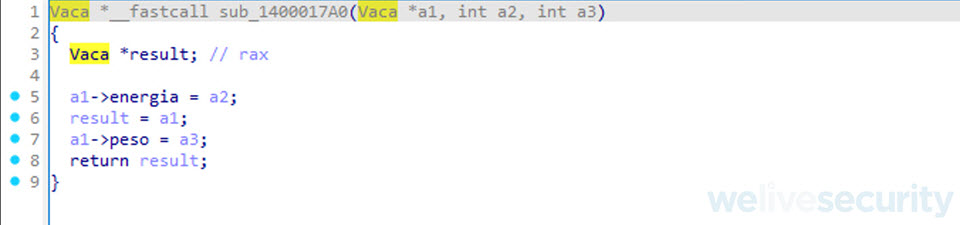
Actualización de la vista del decompilador
Una vez que hemos aplicado el cambio, IDA Free procede a actualizar la vista del decompilar con el nuevo tipo de dato, en caso de que esto no ocurra hay que apretar la tecla “F5”. Como podemos ver ilustración anterior, ahora nuestro código se ve más similar al código fuente y a su vez se vuelve mucho más legible y fácil de interpretar.
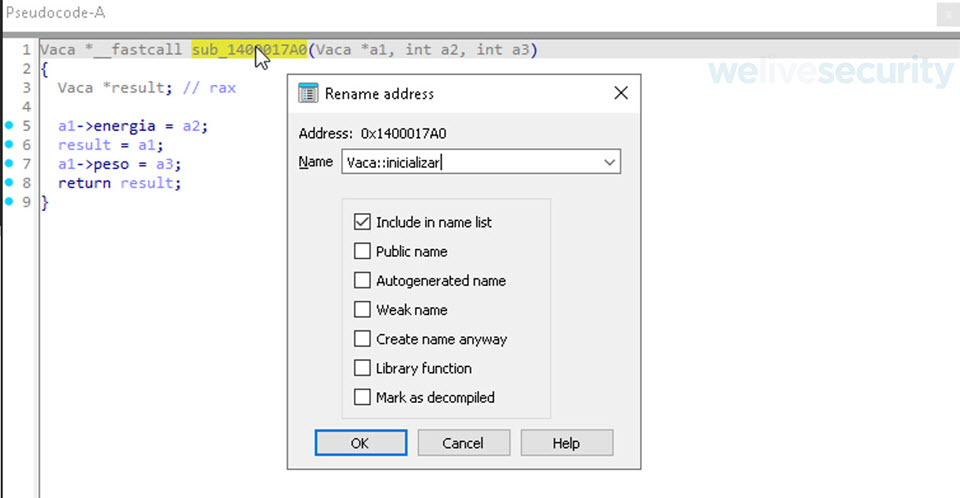
Renombrar subrutina
Acto seguido nos falta renombrar esta subrutina por el nombre utilizado en el código fuente, para ellos nos posicionamos en la pestaña del decompilador sobre el nombre de la subrutina y apretando la tecla “n” IDA nos va a mostrar una nueva pestaña donde procederemos a cambiar el nombre la subrutina por “Vaca::Inicializar”.
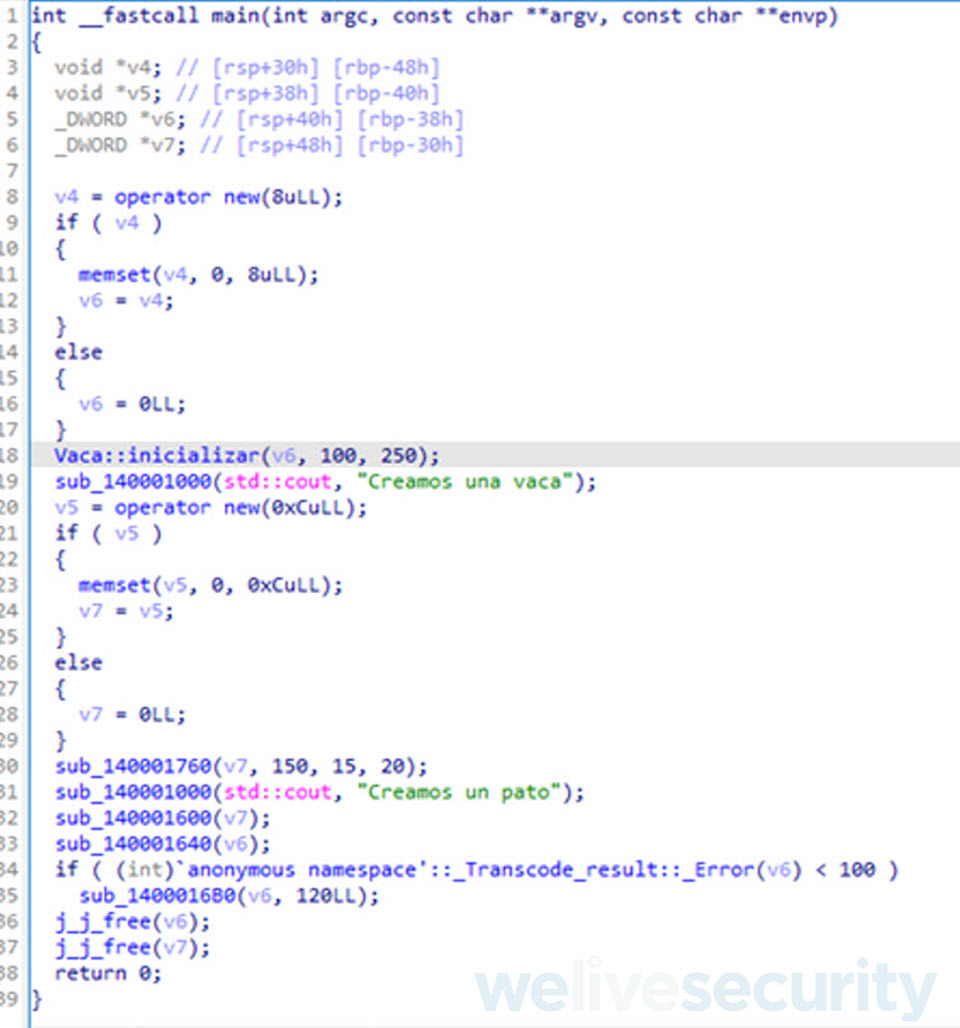
Inferencia de tipos de variables
De la ilustración anterior, podemos inferir ahora que las variables v4 y v6 son del tipo Vaca ya que son utilizadas para crear el objeto de esta clase. Por otro lado, las variables v5 y v7 van a ser utilizadas para un objeto de la clase Pato.
Creación de la estructura Pato
Ahora que ya tenemos creada la estructura Vaca, tenemos que crear la estructura del Pato. Para ello vamos a repetir el procedimiento anterior, pero en este caso cuando fijemos el tamaño de la estructura tenemos que tener en cuenta que va a tener 3 variables de 4 bytes cada una por lo tanto tenemos una estructura de 12 bytes que en hexadecimal 12 es 0xC.

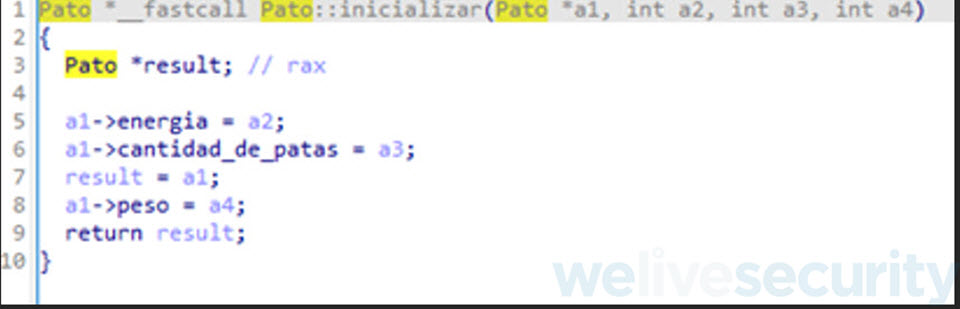
Reemplazo de tipo de dato
Con esta nueva estructura procedemos a reemplazar el tipo de dato utilizado de la variable a1 sobre la subrutina encargada de inicializar el pato, sub_140001760. Indicando que la misma ahora es un puntero al tipo de dato Pato. A su vez renombramos la subrutina por su nombre original “Pato::inicializar”.
Renombrar métodos y atributos
Ahora que ya tenemos nuestras estructuras creadas solo nos falta ir reemplazando dentro de los métodos los tipos de datos y renombrando los métodos por un nombre más descriptivo, como lo hemos mostrado anteriormente.
En este caso dado que tenemos el código fuente, utilizaremos los mismos nombre para los atributos y métodos.
La siguiente captura de pantalla muestra el pseudocodigo decompilado del método main luego de renombrar sus métodos y los tipos de dato.
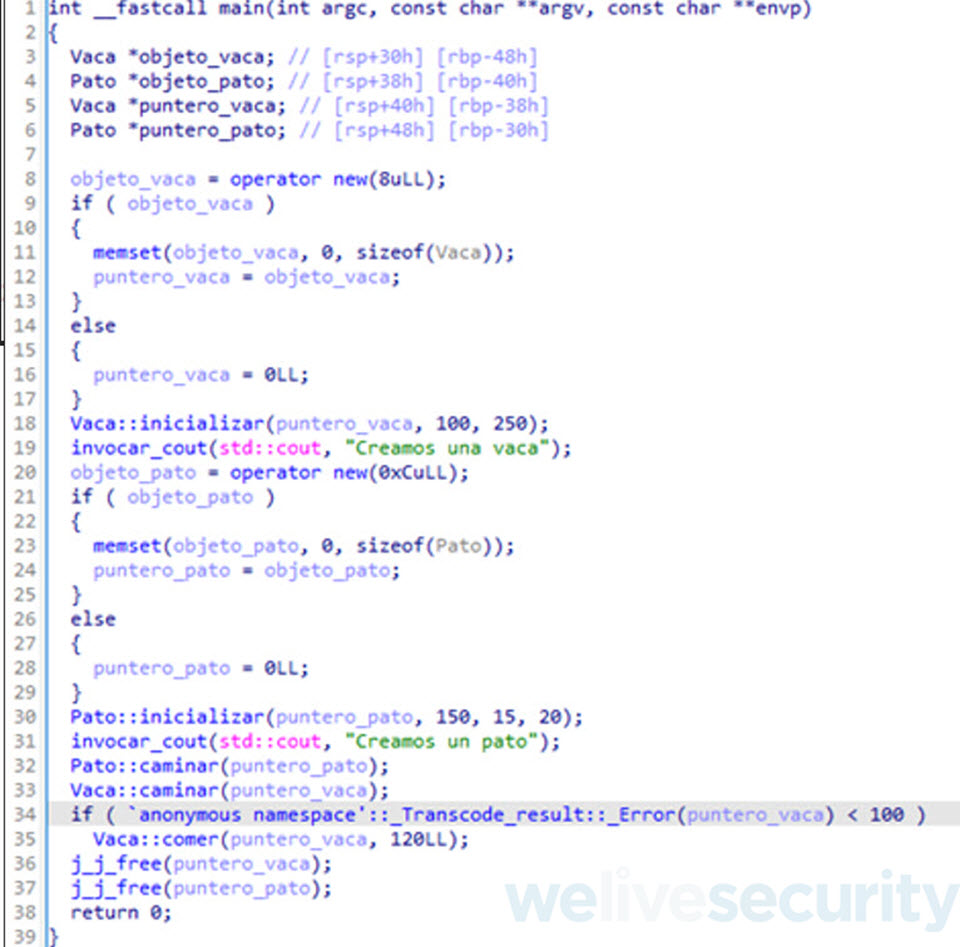
Corrección de renombramientos automáticos
Por último, si miramos la ilustración anterior vemos que en la línea 34 tenemos una subrutina renombrada automáticamente por IDA Free, Anonymous namespace ::_Transcode_result:: Error. En este caso este renombramiento es incorrecto porque si revisamos nuestro código fuente, vemos que en realidad esa subrutina se corresponde con el método “obtener_peso” de la clase Vaca. Esto nos demuestra que a veces tenemos que inspeccionar el código cada subrutina para determinar si es código de librería o código de nuestra aplicación.
2. Segundo ejemplo…. malware
Ahora vamos a ver como detectar objetos y crear estructuras sobre una muestra de malware, donde solamente tenemos el binario y no tenemos acceso al código fuente del mismo para poder ayudarnos y guiarnos en nuestro análisis.
Utilizaremos la muestra con hash DD2F8BF8D9F0B787267ECCAAD64D30D101E6B838 detectada por nuestras soluciones de seguridad como Win64/Agent.ACC. La misma fue compilada para x64 y desarrollada con C++.
Análisis de rutina puntual
Dado que realizar un análisis completo de una muestra de malware es una tarea que lleva tiempo y se escapa del objetivo de este post, vamos a ver una rutina puntual de este código malicioso e intentar reconstruir una clase por medio de estructuras.
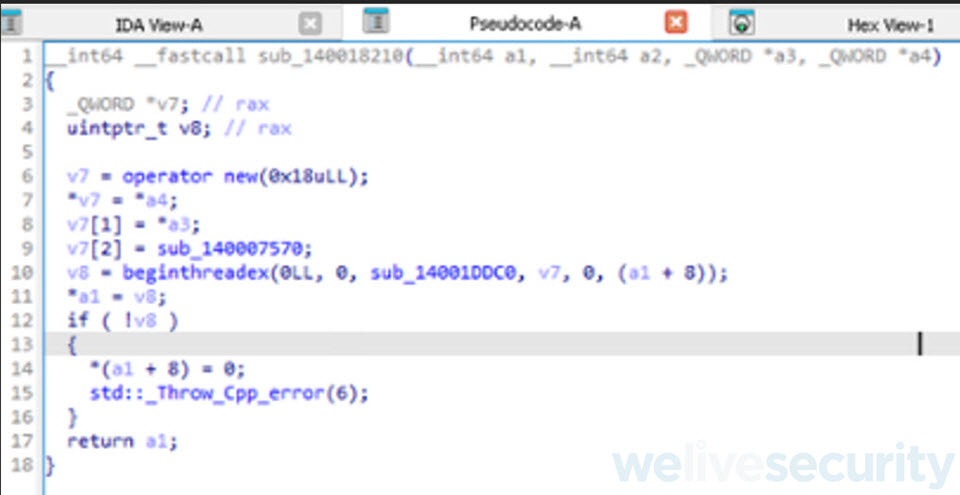
Creación de estructura mi_estructura
En la ilustración anterior podemos ver que se crea una variable v7 que va a ser un objeto que posee un tamaño de 24 bytes, 0x18 en hexadecimal. Luego vemos que a este objeto se le van a ir cargando unos valores sobre sus atributos, pero vuelve a pasar algo similar a lo que habíamos visto antes, la variable es tratada como un array en vez de como un objecto y el decompilador de IDA Free en vez de generarnos algo del estilo “v7->atributo” nos muestra “v7[1]”.
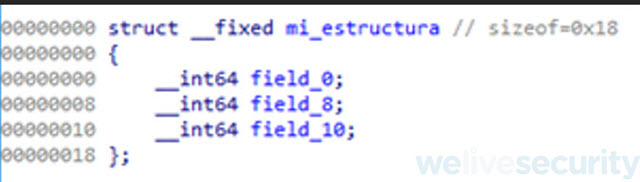
Entonces nuestro próximo paso es crear una estructura a la que le vamos a poner de nombre mi_estructura, la misma tiene que tener un tamaño de 0x18 bytes y a su vez, vemos que el tipo de dato de cada atributo el del tipo QWORD ósea 8 bytes.
Esto por un lado se ve porque los valores a3 y a4 tienen ese tipo de dato y también porque en un momento le asigna a uno de sus atributos un puntero a una funcion. Como el malware esta compilado en x64, los punteros a funciones son de 8 bytes (QWORD).
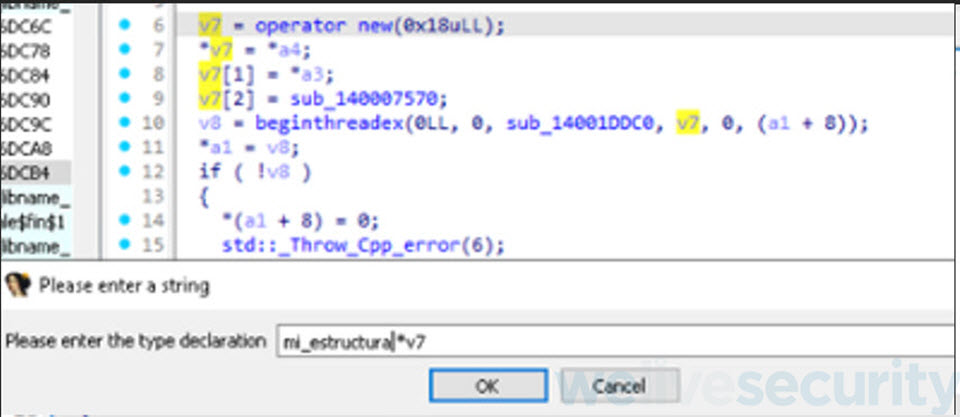
Modificación del tipo de dato
Una vez que tenemos declara nuestra estructura tenemos que volver sobre nuestra subrutina y pararnos sobre la variable v7 y apretando la tecla “y” vamos a poder modificar su tipo de dato por el de nuestra estructura creada.
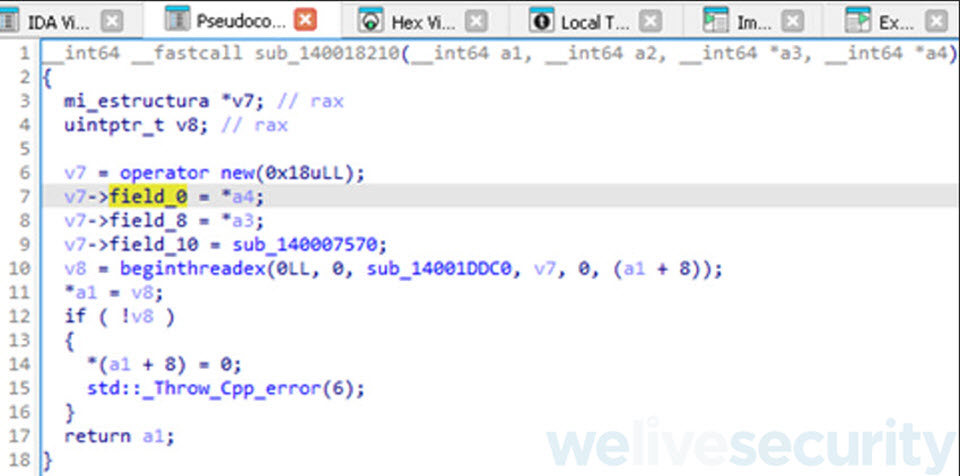
Renombrar atributos
Ahora que tenemos nuestra nueva estructura aplicada sobre la variable v7, por un lado podemos renombrar el atributo field_10 por algo más expresivo como ptr_a_funcion. A su vez, falta determinar que son o para que son utilizados los dos atributos faltantes para poder renombrarlos por un nombre más expresivo.
Análisis de subrutina
Finalizada la asignación de valores a los atributos de la variable v7, vemos que la subrutina llama a la función beginthreadex pasándole la subrutina a ejecutar sub_14001DDC0 y le pasa como argumento nuestra variable v7. Veamos el contenido de esta subrutina.
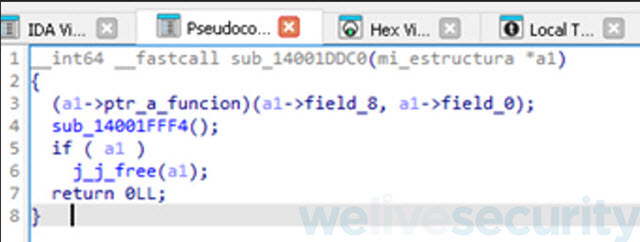
Análisis de atributos
Como vemos en la ilustración anterior, la subrutina termina ejecutando la función guardada en un atributo de nuestra estructura y a su vez le pasa como argumento los dos atributos que nos faltan renombrar. Veamos entonces, el contenido de la función o subrutina a la que apunta este atributo, sub_140007570.
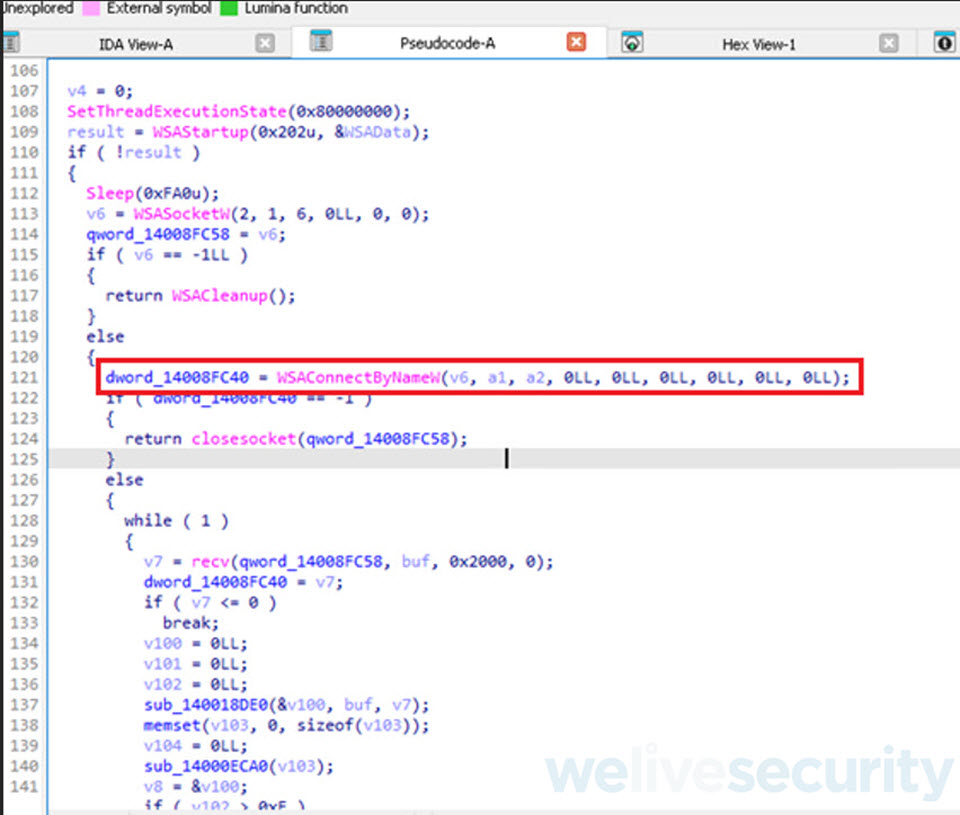
Documentación de la API WSAConnectByNameW
Como vemos en la ilustración anterior, nuestros atributos son utilizados para llamar a la API de Windows WSAConnectByNameW, a continuación tenemos que buscar en la documentación de Microsoft que hace esta API y que atributos recibe.
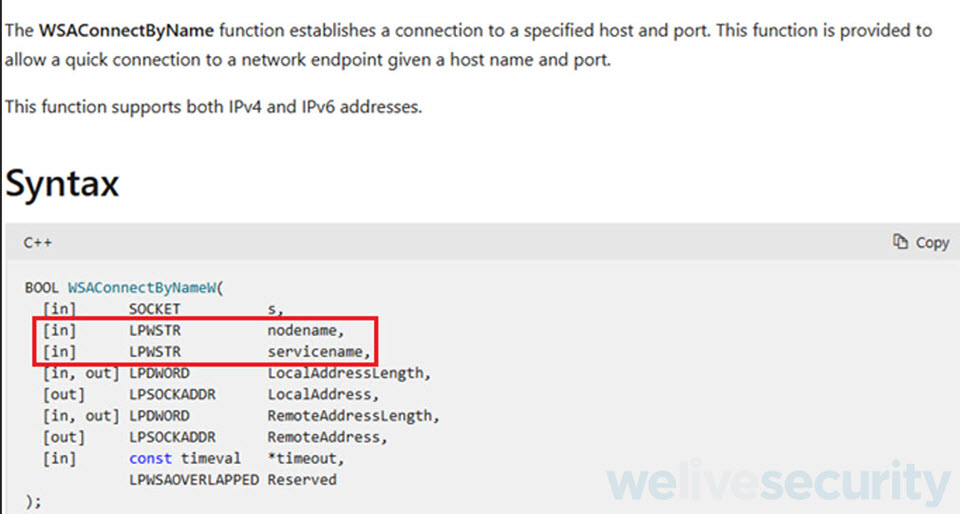
Renombrar atributos
De la documentación de Microsoft, vemos que esta API de Windows se encarga de establecer una conexión sobre un host y puerto determinados. A su vez podemos obtener los nombres de los atributos que nos faltaban.
En base a esta y otras APIs de Windows como WSASocketW, recv que son llamadas sobre la rutina sub_140007570 podemos determinar que esta subrutina muy probablemente trate de establecer un tipo de comunicación hacia un servidor, recibir información del mismo y manipularla.
Ahora solo nos queda por ultimo renombrar los atributos field_8 por nodename y field_0 por servicename y nos quedaría nuestra estructura terminada.
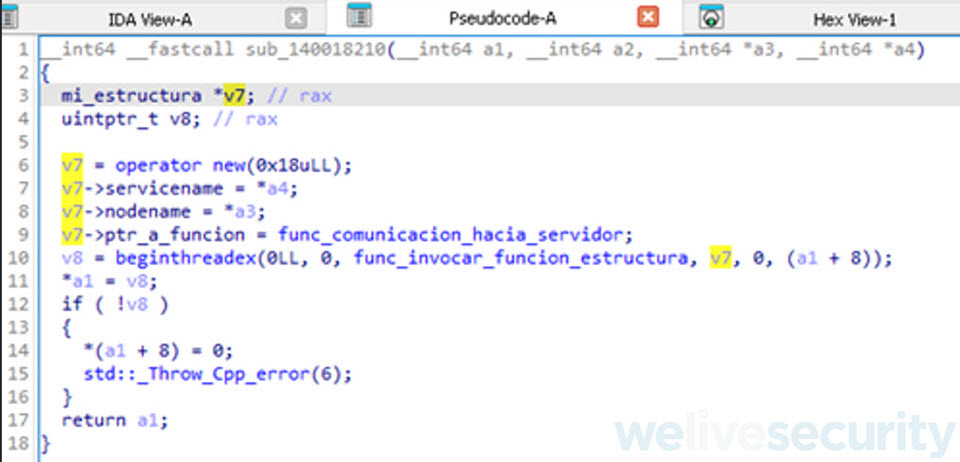
Conclusión
El análisis de malware desarrollado en C++ puede ser una tarea ardua y extensa, en especial si el malware hace un uso intenso de clases y de otras características como la ofuscación de código. La creación de estructuras nos permite reconstruir clases que hayan sido utilizadas en un malware y obtener un código decompilado más legible que nos ayude a entender mejor la actividad maliciosa de un malware.
Esto último muchas veces puede ser un desafío porque al no contar con el código fuente, uno no sabe con exactitud el nombre de las clases y los atributos ya que toda esa información se pierde al momento de compilar un código a un archivo ejecutable.







