

Embora tenhamos falado várias vezes sobre Machine Learning (em português, aprendizado de máquina) e até mesmo sobre nosso produto Augur, desta vez faremos uma pequena revisão teórica para aqueles que não estão tão familiarizados com essa tecnologia.
O que é Machine Learning?
O Machine Learning (ML) é um ramo da ciência que permite que computadores realizem tarefas sem serem explicitamente programadas através de um conjunto de técnicas. Por meio do ML, os computadores podem generalizar seu comportamento a partir de dados processados, a fim de fazer previsões sobre dados futuros.
Para contextualizar, o termo Machine Learning existe há várias décadas, quando Arthur Samuel o utilizou pela primeira vez nos laboratórios da IBM em 1959 e o definiu como: “o campo de estudo que permite que computadores aprendam sem que sejam programados explicitamente”.
Entretanto, foi somente nos anos 80 que esse conceito ganhou impulso com o surgimento das redes neurais artificiais (ANN - Artificial Neural Network) e depois de mais uma década ele começou a ser utilizado por vários especialistas com o objetivo de resolver alguns dos problemas da vida cotidiana.
Similar ao que aconteceu no início de 2010 com as tecnologias Cloud quando muitos consideraram que não iriam ganhar impulso, o mesmo aconteceu com o ML. Atualmente essa ciência é utilizada por várias empresas: Facebook, Netflix, YouTube, Google ou Amazon, para citar algumas.
Os sistemas mais populares que utilizam o Machine Learning são o reconhecimento de voz e facial, a interpretação de perfil do cliente em marketing, a pesquisa de mercado, e a este último está se unindo a automação para IoT, carros autônomos e até mesmo os famosos robôs de ajuda.
Agora, a questão central é: que tipo de necessidades o Machine Learning poderia satisfazer na indústria da cibersegurança? Para responder a essa pergunta, precisamos primeiro apresentar uma pequena estrutura teórica para entender onde o Machine Learning poderia ser aplicado em cibersegurança.
Como o ML geralmente é classificado?
Em termos gerais, o ML pode ser classificado da seguinte forma:
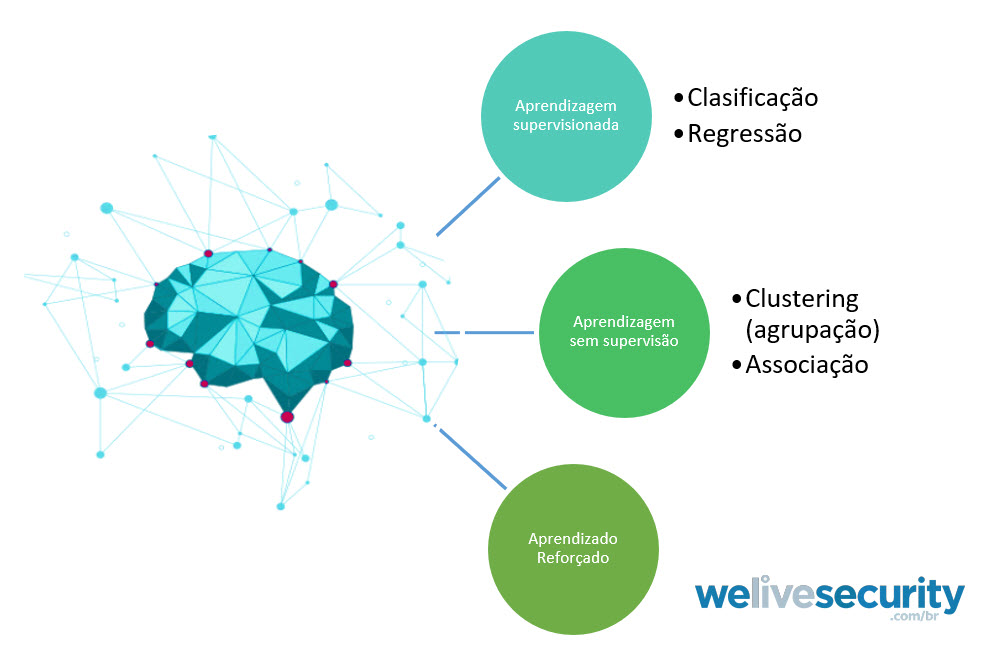
Figura 1. Classificação geral do Machine Learning.
Embora, como mostrado na figura acima, existam vários algoritmos de Machine Learning, neste post discutiremos dois deles para entender como podem ser usados no campo da cibsergurança:
Aprendizagem supervisionada: está enfocada em determinar as probabilidades de novos eventos com base em eventos observados anteriormente. Dentro deste algoritmo, existem duas outras categorias:
- Classificação: os algoritmos de classificação predizem a que categoria uma entrada pertence com base nas probabilidades aprendidas com entradas previamente observadas. Por exemplo: determinar se um arquivo é malware ou não.
- Regressão: os modelos de regressão (linear, logística) prevêem um valor de saída para uma determinada entrada com base nos valores de saída associados às entradas anteriores. Por exemplo: prever quantas amostras de malware serão detectadas no próximo mês.
Aprendizagem sem supervisão: tentam encontrar padrões não rotulados. Por exemplo: determinar quantas famílias de malware existem no conjunto de dados e quais arquivos pertencem a cada família. Dentro deste tipo de ML está o “Clustering”, que consiste em agrupar um conjunto de objetos (cluster) por suas semelhanças. Exemplo: detecção de anomalias, ou famílias de malware.
Etapas do Machine Learning
Mesmo que você não seja um especialista nesse tipo de tecnologia, é importante entender como funciona o processo do ML de uma forma mais geral, que se divide nas seguintes etapas:

Figura 2. Ciclo geral do Machine Learning.
- Coleta de dados: qualquer que seja o algoritmo ML a ser usado, é necessário contar com uma grande quantidade de dados para treinar o nosso modelo. A maioria dos dados vem de uma variedade de fontes.
- Pré-processamento: muitas vezes os dados coletados são categóricos, portanto é necessário realizar um pré-processamento e transformar esses dados em numéricos, já que os algoritmos do ML funcionam somente com dados numéricos.
- Extração de características: são identificados os elementos a serem extraídos e submetidos a análise.
- Seleção de características: identificação dos atributos necessários para treinar o modelo do ML.
- Treinamento: o modelo é treinado com base no algoritmo do ML selecionado. Nesta etapa, parte dos dados é usada para treinar o modelo e parte dos dados é usada para avaliar o modelo.
- Teste: esta é considerada por muitos especialistas como a etapa mais importante, uma vez que, tendo treinado o modelo, o modelo deve ser validado. Para isso, os dados que foram separados na etapa anterior, dados de validação, são usados para executar o modelo do ML e avaliar se o modelo fornece os resultados esperados.
- Análise dos resultados: nesta etapa, são pesquisados erros para corrigir e ajustar o modelo.
Tendo explicado os tipos de ML que existem e suas etapas, vamos agora detalhar as áreas nas quais essa tecnologia pode ser usada dentro do campo da cibersegurança.
Áreas da cibersegurança nas quais o Machine Learning está sendo aplicado
Em geral, os produtos de aprendizagem de máquinas são construídos para prever ataques antes que eles ocorram, mas dada a natureza sofisticada desses ataques, as medidas preventivas muitas vezes falham. Nesses casos, o aprendizado de máquinas ajuda a remediar de outras formas, como o reconhecimento do ataque em suas etapas iniciais e a prevenção de sua propagação por toda a organização. A figura abaixo identifica as necessidades que o ML pode atender dentro da cibergurança:
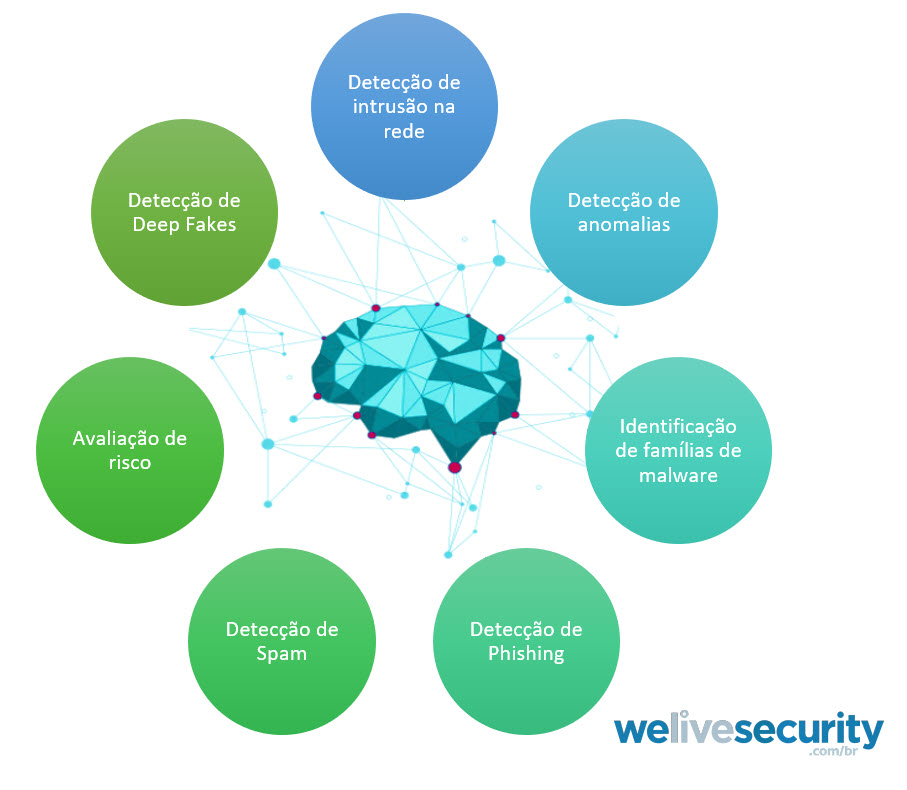
Figura 3. O Machine Learning aplicado à cibersegurança.
O lado B do Machine Learning
Por enquanto, falamos apenas sobre como o Machine Learning pode se tornar um aliado no campo da cibersegurança, mas não podemos esquecer que o ML é atualmente utilizado em várias áreas. Por exemplo: reconhecimento facial, no campo da genética, compressão de texto, veículos e robôs autônomos, análise de imagem, detecção de fraudes, previsão de tráfego, seleção de clientes, posicionamento em buscadores, reconhecimento de voz, entre outros aplicativos. No entanto, todos esses tipos de aplicativos funcionam com base no processamento de enormes quantidades de dados.
A pergunta então é: Um modelo de Machine Learning pode ser violado por cibercriminosos? A resposta é: sim.
Da mesma forma que os modelos de prevenção para diferentes tecnologias são estudados dentro da cibersegurança, a aplicação do ML a esses modelos está agora começando a ser focada. É por isso que o conceito de Adversarial Machine Learning está ganhando mais relevância no campo da cibersegurança.
O que é Adversarial Machine Learning?
O termo "adversário" é usado no campo da cibersegurança para descrever o procedimento pelo qual é feita uma tentativa de penetrar ou corromper uma rede.
Neste caso, os adversários podem usar uma variedade de métodos de ataque para interromper um modelo de aprendizagem da máquina, seja durante a fase de treinamento (chamado de ataque de “poisoning” ou envenenamento) ou após o classificador ter sido treinado (um ataque de "evasão").
Conclusões
Nos últimos anos, o termo Machine Learning tem se tornado cada vez mais importante para os sistemas, é claro que é um tipo de tecnologia em crescimento e tem muitos benefícios para vários setores. Na área de cibersegurança, o ML pode ser usado na Threat Intelligence; por exemplo, na detecção de ameaças, já que essa área produz um grande volume de dados.
Além disso, o ML está sendo procurado para a áreas de Threat Hunting e para a classificação precisa das famílias de malware.
Sem dúvida, essa tecnologia é um grande aliado para muitos setores, mas existe a possibilidade de que esses modelos de inteligência de dados possam ser modificados e que isso possa afetar seriamente o negócio que utiliza essa tecnologia. Em um post que publicamos nos próximos meses, falaremos sobre o Adversarial Machine Learning.
Caso queira se aprofundar no ML dentro da área de cibersegurança, confira algumas leituras adicionais:



