

The Morris worm of 1988 was one of those industry-shaking experiences that revealed how quickly a worm could spread using a vulnerability known as a buffer overflow or buffer overrun. Around 6,000 of the 60,000 computers connected to ARPANET, a precursor to the Internet, were infected with the Morris worm. Although a few positives came from this attack, especially in pushing software vendors to take vulnerabilities seriously and in the creation of the first Computer Emergency Response Team (CERT), this attack was far from the last to capitalize on a buffer overflow.
In 2001, the Code Red worm infested more than 359,000 computers running Microsoft’s IIS software. Code Red defaced webpages and attempted to launch denial-of-service attacks, including one on a White House web server.
Then, in 2003, the SQL Slammer worm attacked more than 250,000 systems running Microsoft’s SQL Server software. SQL Slammer crashed routers, significantly slowing down or even stopping network traffic on the internet. Both the Code Red and SQL Slammer worms spread via buffer overflow vulnerabilities.
More than thirty years on from the Morris worm, we are still plagued by buffer overflow vulnerabilities with all their negative consequences. Although some blame various programming languages, or features of them, as having an unsafe design, the culprit seems to be more the fallible use of these languages. To understand how buffer overflows happen, we need to know a little about memory, especially the stack, and about how software developers need to manage memory carefully when writing code.
What is a buffer and how does a buffer overflow occur?
A buffer is a block of memory assigned to a software program by the operating system. It is a program’s responsibility to request, from the operating system, the amount of memory that it needs to run correctly. In some programming languages like Java, C#, Python, Go, and Rust, memory management is handled automatically. In other languages like C and C++, programmers have the burden of manually managing the allocation and freeing of memory and ensuring that memory bounds are not crossed by checking buffer lengths.
However, whether by programmers who use code libraries incorrectly or by those who are writing them, mistakes can be made. These are the cause of many software vulnerabilities ripe for discovery and exploit. A correctly designed program should specify the maximum size of memory to hold data and guarantee that this size is not exceeded. A buffer overflow happens when a program writes data beyond the memory assigned to it and into a contiguously located memory block intended for some other use or owned by some other process.
As there are two main types of buffer overflows — heap-based and stack-based — a prefatory word is in order concerning the difference between the heap and the stack.
The stack vs. the heap
Before a program executes, the loader assigns it a virtual address space that includes addresses for both the heap and the stack. The heap is a block of memory that is used for global variables and variables assigned memory at runtime (dynamically allocated).
Much like a stack of plates at a buffet, a software stack is built out of frames that hold a called function’s local variables. Frames are pushed (put onto) the stack when functions are called and popped off (removed from) the stack when they return. If there are multiple threads, then there are multiple stacks.
A stack is very fast compared to a heap, but there are two downsides of using the stack. First, stack memory is limited, meaning that placing large data structures on the stack more quickly exhausts the available addresses. Second, each frame has a lifetime that is limited to its existence on the stack, meaning that it is not valid to access data from a frame that has been popped off the stack. If multiple functions require access to the same data, it is better to place the data on the heap and pass a pointer to that data (its address) to those functions.
Buffer overflows can happen in both the heap and the stack, yet we will focus here on the more common variety: stack-based buffer overflows.
Stack-based buffer overflows: Overwriting the return address
As frames are stacked on top of each other with each function call, return addresses are also pushed onto the stack, telling the program where to continue execution when a called function completes:
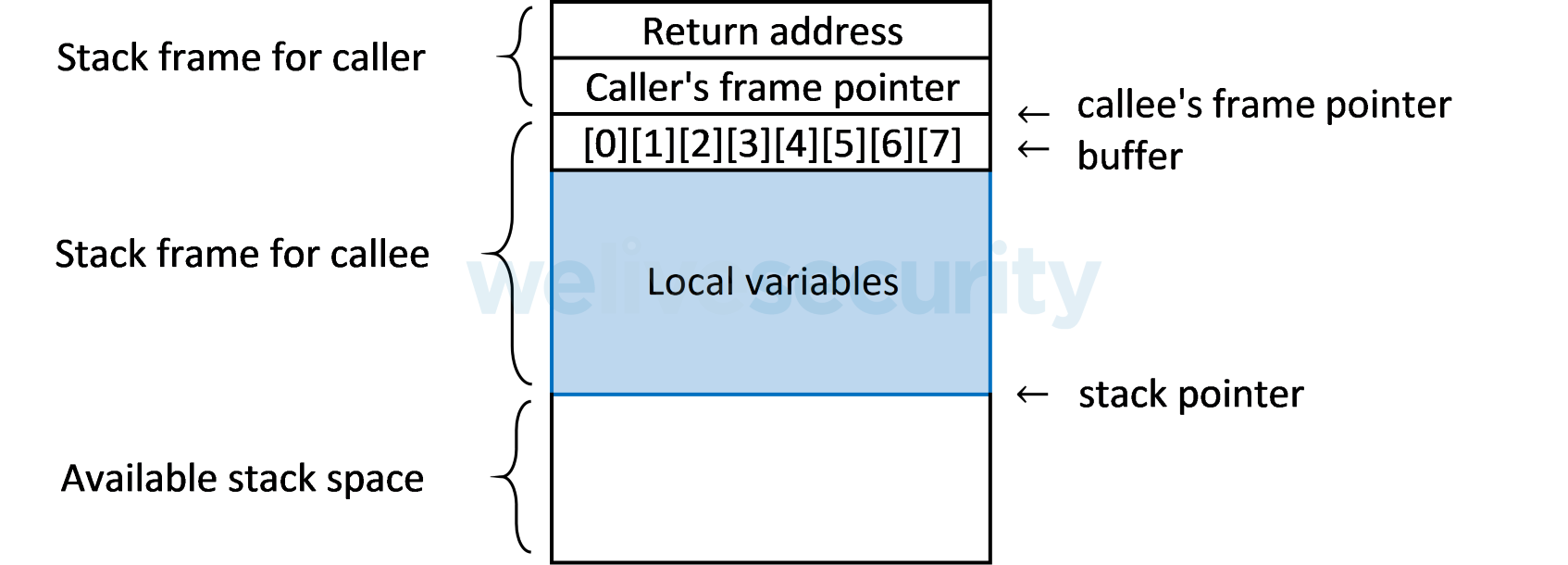
The return address is located near the buffers that hold the local variables. Hence, if a malicious program succeeds in writing more data into a buffer than it can hold, then a buffer overflow happens. Data that does not fit into the intended buffer can overflow into the return address and overwrite it.
Should a buffer overflow occur in the typical use of a vulnerable program, most often, the new value of the overwritten return address is not a valid memory location, meaning that the program generates a memory segmentation error and will require error recovery — if this is not possible, the program may become unstable or even crash when it attempts to return from the function whose stack frame has been altered by the overflow. However, cybercriminals can take advantage of buffer overflows to overwrite the return address with a valid memory location that points directly to their malicious code, thus enabling them in many cases to launch shells and take complete control of victim computers. The Stuxnet worm, for example, used a buffer overflow vulnerability to launch a root shell.
Some exploit code even takes a clever approach of repairing the damage to the stack after performing a malicious action so as to restore the original return address. In this way, the attackers attempt to obfuscate the hijacking of the return instruction, letting the program run as expected afterward.
Example – Encoding hexadecimal characters as byte values
For software developers interested in a recent buffer overflow discovered in 2021, we offer the following code in C, which is a simplified and rewritten version of a vulnerability in the ZTE MF971R LTE router tracked as CVE‑2021‑21748:
#include <stdio.h>
#include <string.h>
void encodeHexAsByteValues(const char *hexString, char *byteValues) {
signed int offset = 0;
int hexValues = 0;
int byte = 0;
while (offset < strlen(hexString)) {
strncpy((char *) &hexValues, &hexString[2 * offset], 2u);
sscanf((const char *) &hexValues, "%02X", &byte);
byteValues[offset++] = byte; // The return address can be overwritten opening a path for the
// insertion of exploit code
}
}
int main(void) {
const char* hexString = "0123456789ABCDEF01234";
char byteValues[4];
encodeHexAsByteValues(hexString, byteValues); // There is no size check to ensure that
// hexString is not too long for byteValues
// before calling the function
return 0;
}For more, see my Google Colaboratory notebook.
The program above demonstrates a function that encodes a string consisting of hexadecimal-compatible characters into a form with half the memory requirement. Two characters can stand in as actual byte values (in hexadecimal), so that the characters ‘0’ and ‘1’, represented with the byte values 30 and 31, respectively, can be represented literally as the byte value 01. This functionality was used as part of the ZTE router’s handling of passwords.
As noted in the comments of the code, the hexString, having a size of 21 characters, is too large for the byteValues buffer, which only has a size of 4 characters (even though it can accept up to 8 characters in encoded form), and there is no check to ensure that the encodeHexAsByteValues function won’t lead to a buffer overflow.
Protecting against buffer overflow attacks
Aside from careful programming and testing on the part of software developers, modern compilers and operating systems have implemented several mechanisms to make buffer overflow attacks more difficult to perform. Taking the GCC compiler driver for Linux as an example, we will briefly mention two mechanisms it uses to hinder the exploitation of buffer overflows: stack randomization and stack corruption detection.
Stack randomization
Part of the success of buffer overflow attacks relies on knowing a valid memory location that points to the exploit code. In the past, stack locations were fairly uniform as the same combinations of programs and operating system versions would have the same stack addresses. This meant that attackers could orchestrate one attack — much like one strain of a biological virus — to attack the same program-operating system combination.
Stack randomization allocates a random amount of space on the stack at the start of a program’s execution. This space is not meant to be used by the program but to allow the program to have different stack addresses at each execution.
However, a persistent attacker can overcome stack randomization by repeatedly attempting different addresses. One technique is to use a long sequence of NOP (no operation) instructions, which merely increase the program counter, at the start of the exploit code. Then the attacker only needs to guess the address of any one of the many NOP instructions, instead of having to guess the exact address of the start of the exploit code. This is called a “NOP sled” because once the program jumps to one of these NOP instructions, it slides through the rest of the NOPs until the actual start of the exploit code. The Morris worm, for example, started with 400 NOP instructions.
An entire class of techniques called address-space layout randomization exists to ensure other parts of a program, like the program code, library code, global variables, and heap data, have different memory addresses each time the program is run.
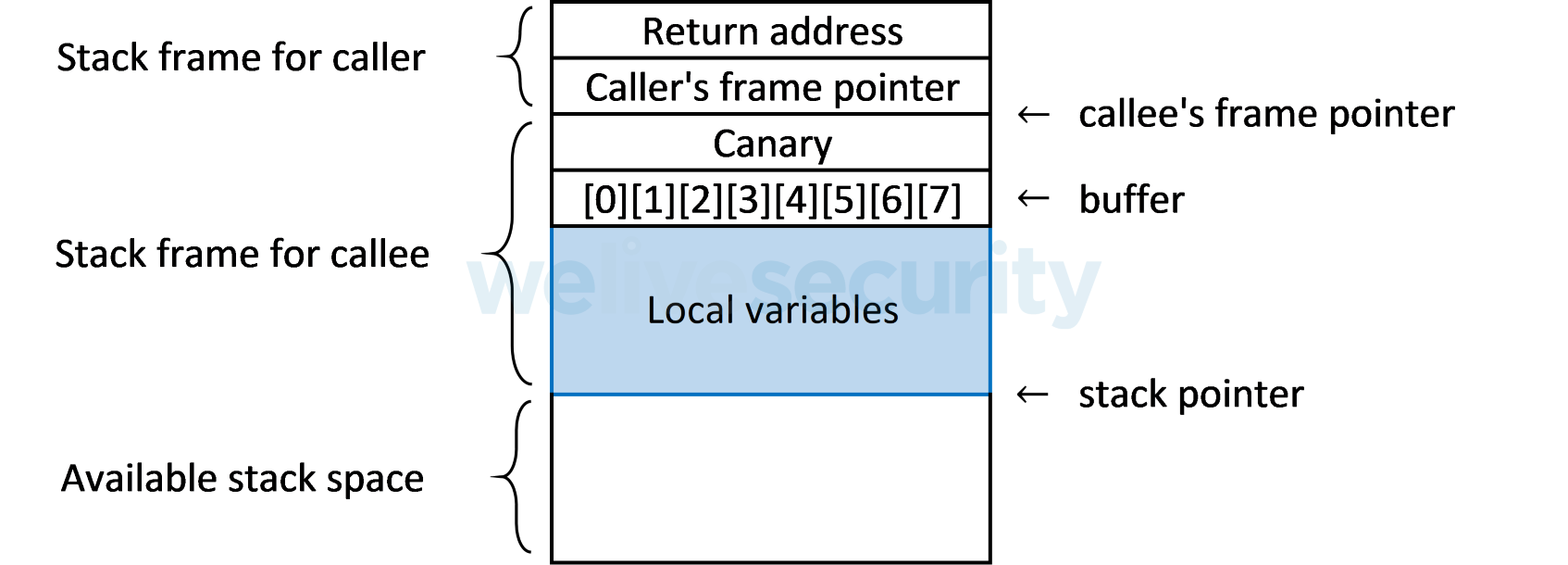
Stack corruption detection
Another method to prevent a buffer overflow attack is to detect when the stack has become corrupted. A common mechanism is known as a stack protector, which inserts a random canary value, also called a guard value, between the local buffers of a stack frame and the rest of the stack. Before returning from a function, the program can then check the state of the canary value and call an error routine if a buffer overflow has changed the canary value.
Final advice
As buffer overflow vulnerabilities continue to be discovered and fixed, the best advice is to have a robust policy in place to patch all applications and code libraries with the highest priority. Coupling your updating policy with the deployment of security solutions that can detect exploit code can dramatically up the ante against attackers attempting to exploit buffer overflows.
Additional reading:
Programmer’s Day: Resources to audit your code
Some examples of vulnerable code and how to find them



