
Luego de haber estado reconociendo estructuras comunes en ingeniería reversa (parte I y parte II) hace algunas semanas, continuaremos con la útil tarea de vislumbrar patrones entre las diversas líneas de código. Hoy es el turno de los bucles, esas estructuras que permiten la ejecución repetida de las instrucciones.
Dado que, al realizar reversing, la cantidad de instrucciones de un programa puede ascender a los cientos de miles, resulta muy poco práctico realizar un análisis instrucción por instrucción. Por eso, se hace necesario lograr cierto nivel de abstracción en el proceso; con un poco de práctica podemos acostumbrarnos a ver un amplio panorama de lo que hace el código, mediante el análisis de grupos de instrucciones en lugar de instrucciones individuales. Asimismo, si pensamos en lenguajes de alto nivel, nos daremos cuenta de que existen estructuras o construcciones que, al ser combinadas, le dan funcionalidad a un programa. Entre esas construcciones encontramos aquellas que rigen el flujo de ejecución, como los condicionales, bucles y demás. Si reconocemos estas estructuras entre el código en ensamblador, estaremos más cerca del lenguaje de alto nivel, con todas las ventajas que esto ofrece.
Para poder reconocer bucles entre las líneas de código en lenguaje ensamblador, primero debemos entender la estructura de un bucle en un lenguaje de alto nivel. Por ello, en la siguiente imagen observamos un programa sencillo con un bucle en C:

El código mostrado imprime por pantalla 9 líneas, desde “Contando 1” hasta “Contando 9”. Ahora bien, si nos centramos en el funcionamiento del bucle, podemos bosquejar el siguiente pseudocódigo:
1- Asignar a la variable i el valor 1
2- Si el valor de i es mayor o igual a 10, ir al paso 6. Si es menor que 10, continuar con el paso 3
3- Imprimir por pantalla “Contando i”, con el valor actual de i
4- Sumar 1 a la variable i
5- Ir al paso 2
6- Salir del bucle
Los pasos mostrados se marcan con números en la siguiente imagen. Debemos notar que los números utilizados se corresponden con el pseudocódigo presentado arriba.
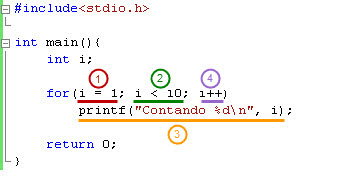
Si ahora trasladamos este ejemplo particular al caso general, notaremos que los bucles contarán con las siguientes secciones:
- La encargada de inicializar las variables
- La que realiza una comparación, en la cual se basa la repetición
- La que contiene el código a ejecutar repetidamente
- Aquella que incrementa la variable de comparación
Por lo tanto, cuando estemos realizando reversing sobre un ejecutable, debemos observar aquellos grupos de instrucciones que se correspondan con estas secciones, prestando especial atención a las instrucciones de salto, el pegamento que une las secciones. Teniendo esto en cuenta, a continuación se muestra el código correspondiente al programa desensamblado:
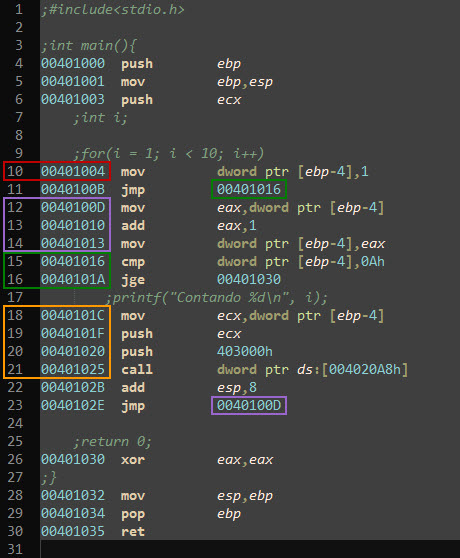
Vemos las cuatro secciones marcadas con distintos colores. En rojo se encuentra la sección de inicialización, que consiste en una sola instrucción mov que asigna el valor 1 a la variable local i que se encuentra en el stack de main. Luego vemos un salto a la sección de comparación, en verde, que comprueba si el valor de i es mayor o igual a 10. De ser así, deja de ejecutar el bucle; caso contrario (si se cumple la condición de iteración, i < 10) continúa con la ejecución. A continuación se pasa a la sección de ejecución, en naranja, que inserta el valor de i junto con la cadena de formato (ubicada en la dirección de memoria 0x403000 en este caso) al stack, para invocar a printf (instrucción call). Por último, se realiza un salto a la sección de incremento, violeta, donde se suma 1 al valor de i.
Ya hemos mencionado las bondades de algunas herramientas como IDA, que nos permiten ver el flujo de ejecución en forma gráfica:
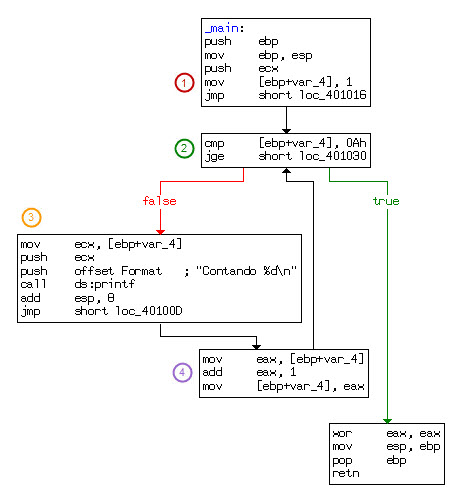
Puede que antes de leer este post dicha estructura gráfica no nos llamara la atención, pero ahora vemos claramente la presencia de las 4 secciones y de la flecha ascendente (del bloque 4 al 2) que nos indica la presencia de un bucle.
Esto es todo por hoy, pero en futuros posts continuaremos analizando otras estructuras de control y de datos. ¡Hasta la próxima!



